
퀀트 투자 자동매매 플랫폼 구축 - Pandas를 활용한 데이터 분석 실습 (4)
“파이썬 증권 데이터 분석” (한빛미디어, 2020) 도서의 Chapter3에서는 NumPy와 Pandas를 학습하고, 서로 다른 자산 간의 상관계수를 계산하고 상관계수를 기반으로 위험 리스크 완화 효과에 대해 알아본다.
NumPy
NumPy (Numerical Python)는 수치 분석 및 통계 연산을 구현하기 위한 Python의 기본 모듈이다. Python에 내장된 데이터 구조를 사용하는 것보다 수치 분석 및 통계 연산이 더 빠르다.
Python - 프로그래밍 기초 학습 (3) 포스팅에서 실습용 패키지를 한 번에 설치했다면 NumPy 라이브러리를 추가로 설치할 필요가 없다. 그렇지 않은 경우 아래 명령을 사용하여 NumPy 라이브러리를 설치할 수 있다.
pip install numpy
또는
pip3 install numpy
NumPy를 설치한 후, 라이브러리에서 제공하는 array(), transpose(), flatten() 등의 함수를 사용하여 예제를 실습해본다. NumPy의 배열은 사칙연산도 가능하며, 브로드캐스팅, 행렬 곱셈을 연습해 본다.
Pandas
Pandas는 NumPy를 기반으로 하는 데이터 분석 라이브러리로, 데이터를 구조화하여 처리할 수 있다. Pandas는 Series, DataFrame, Panel 등의 데이터 구조를 제공하며, 데이터를 불러오고, 저장하고, 조작하는 기능을 제공한다.
아래 명령을 사용하여 Pandas 라이브러리를 설치할 수 있다.
pip install pandas
또는
pip3 install pandas
Pandas Series
pandas의 시리즈(Series)는 모든 유형(정수, 부동 소수점, 문자열 등)의 데이터를 보유할 수 있는 1차원 레이블 배열이다. Python 목록 또는 NumPy 배열과 유사하고 시리즈의 각 요소에는 인덱스라고 하는 해당 레이블이 있다. 이 인덱스를 사용하면 빠르고 효율적인 데이터 검색, 슬라이싱 및 조작이 가능하다.
Series() 함수를 사용하여 시리즈를 생성하고, 인덱스를 사용하여 데이터를 검색하고, 슬라이싱 및 조작하는 방법을 실습해본다.
- example code
- example result
Pandas DataFrame
Pandas 데이터프레임(DataFrame)은 다양한 유형(정수, 부동 소수점, 문자열 등)의 데이터를 보유할 수 있는 2차원 레이블이 지정된 데이터 구조이다. 이는 기본적으로 각 열이 서로 다른 변수나 특성을 나타내고, 각 행이 서로 다른 관측값이나 데이터 포인트를 나타내는 테이블이다. DataFrame은 Python에서 구조화된 데이터를 조작하고 분석하는 방법을 제공한다.
딕셔너리와 시리즈, 리스트를 사용한 DataFrame을 생성하고, 인덱스를 사용하여 데이터를 검색하는 방법을 실습해본다.
야후 파이낸스를 활용한 주식 비교하기
야후 파이낸스(Yahoo Finance)는 주식, 통화, 채권, 상품, 주식 지수 등의 금융 정보를 제공한다. Pandas를 사용하여 야후 파이낸스에서 삼성전자와 마이크로소프트의 주식 데이터를 불러와 주식수익률을 비교해본다.
야후 파이낸스는 아래의 명령어로 설치할 수 있다.
pip install yfinance --upgrade --no-cache-dir
주식 시세 데이터를 가져오기 위한 pandas-datareader (pdr) 라이브러리도 설치한다.
pip install pandas-datareader
주식 시세 데이터를 가져오려면, pdr.get_data_yahoo() 함수를 사용한다. 이 함수는 주식 코드, 시작일, 종료일을 인수로 받아서 주식 시세 데이터를 반환한다.
get_data_yahoo(조회할 주식 종목, [,start=조회 기간의 시작일] [, end=조회 기간의 종료일])
조회한 데이터를 head() 함수를 사용하여 삼성전자 DataFrame의 처음 10개 행을 표시하고 다운로드된 데이터를 확인한다.
head() 함수에 의해 표시되는 데이터에는 OHLC(시가, 고가, 저가, 종가)뿐만 아니라 거래량 및 조정된 종가도 포함되어 있다. 데이터의 용어에 대한 설명은 아래와 같다.
- 시가 (Open) : 특정 거래일에 주식이 처음 거래되는 가격. 이는 거래 세션 시작 시 가격을 나타낸다.
- 고가 (High) : 거래일 동안 주식이 거래되는 최고 가격. 이는 거래 세션 중 어느 시점의 최고 가격을 나타낸다.
- 저가 (Low) : 거래일 동안 주식이 거래되는 최저 가격. 이는 거래 세션 중 어느 시점의 최저 가격을 나타낸다.
- 종가 (Close) : 거래일이 끝날 때 주식이 마감되는 가격. 이는 거래 세션이 끝날 때의 가격을 나타낸다.
- 거래량 (Volume) : 거래량은 특정 거래일, 주, 월 또는 기타 특정 기간 동안 거래된 주식의 총 주식 수를 나타낸다. 이는 선택한 기간 내에 해당 특정 주식에 대한 시장의 활동 및 유동성 수준을 나타낸다. 거래량이 많다는 것은 종종 투자자의 상당한 관심이나 거래 활동을 의미하는 반면, 거래량이 적다는 것은 관심이 적거나 거래 기간이 더 조용하다는 것을 의미한다.
- 조정된 종가 (Adj Close) : 조정 마감은 주식 분할, 배당금, 유상증자 등 가치에 영향을 미칠 수 있는 기업 활동이나 사건을 반영하도록 조정된 주식 마감 가격이다. 이 조정 가격은 투자자와 분석가가 자본 구조나 가치 분포의 변화를 고려하여 시간이 지남에 따라 주식의 실제 성과를 정확하게 추적하는 데 도움이 된다. 조정 마감 가격은 과거 성과를 비교하고 기술적 분석을 수행하는 데 특히 유용하다.
삼성전자의 액면 분할 이후 시점인 2018년 5월 4일부터 주식 시세 데이터를 가져오고, 마이크로소프트의 주식 시세 데이터를 가져와 삼성전자와 마이크로소프트의 주식수익률을 비교해본다. 비교한 내용을 그래프로 표현하기 위해 matplotlib 라이브러리를 활용한다.
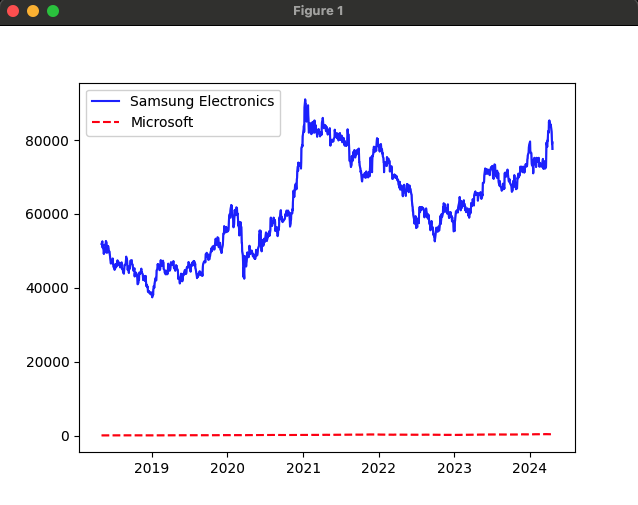
x축은 연도별 지수를 나타내고, y축은 DataFrame의 종가 데이터를 나타냅니다. 삼성전자와 마이크로소프트의 가격을 그래프로 그려보면 가격의 수치 차이가 꽤 커서 마이크로소프트 주가는 거의 0에 가까운 직선으로 나타난다. 이 그래프만으로는 주식 수익률을 비교하기가 어렵기 때문에 다음에는 일간 변동률을 이용하여 가격을 비교하는 방법을 살펴본다.
일간 변동률을 구하면 가격이 다른 두 주가의 수익률을 비교할 수 있다. 일간 변동률은 다음과 같이 계산한다.

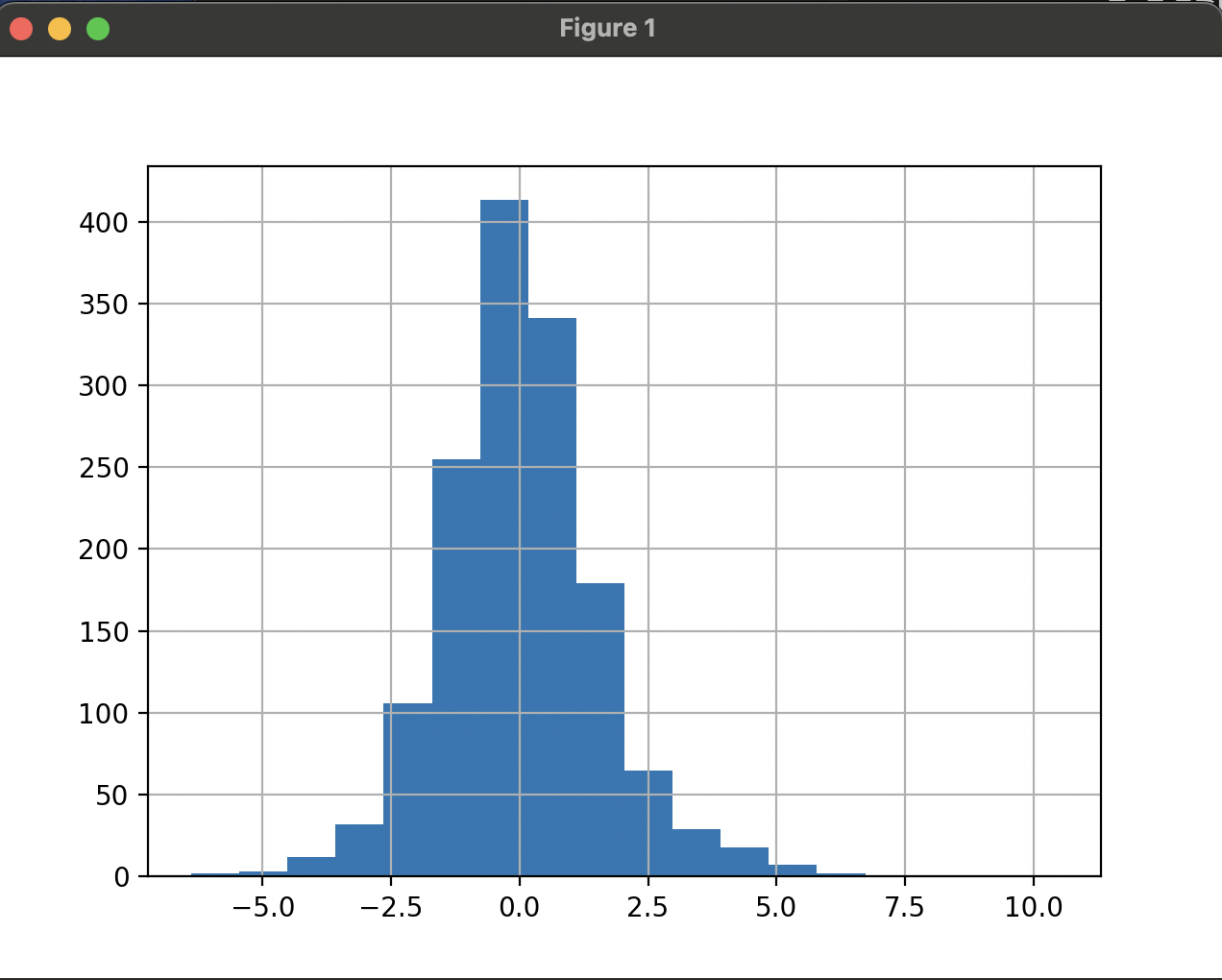
Series 에서 제공하는 shift() 함수를 사용하여 일간 변동률을 계산해보고, 히스토그램을 활용하여 도수 분포를 그래프로 확인해본다.
- 삼성전자 종가의 일간 변동률
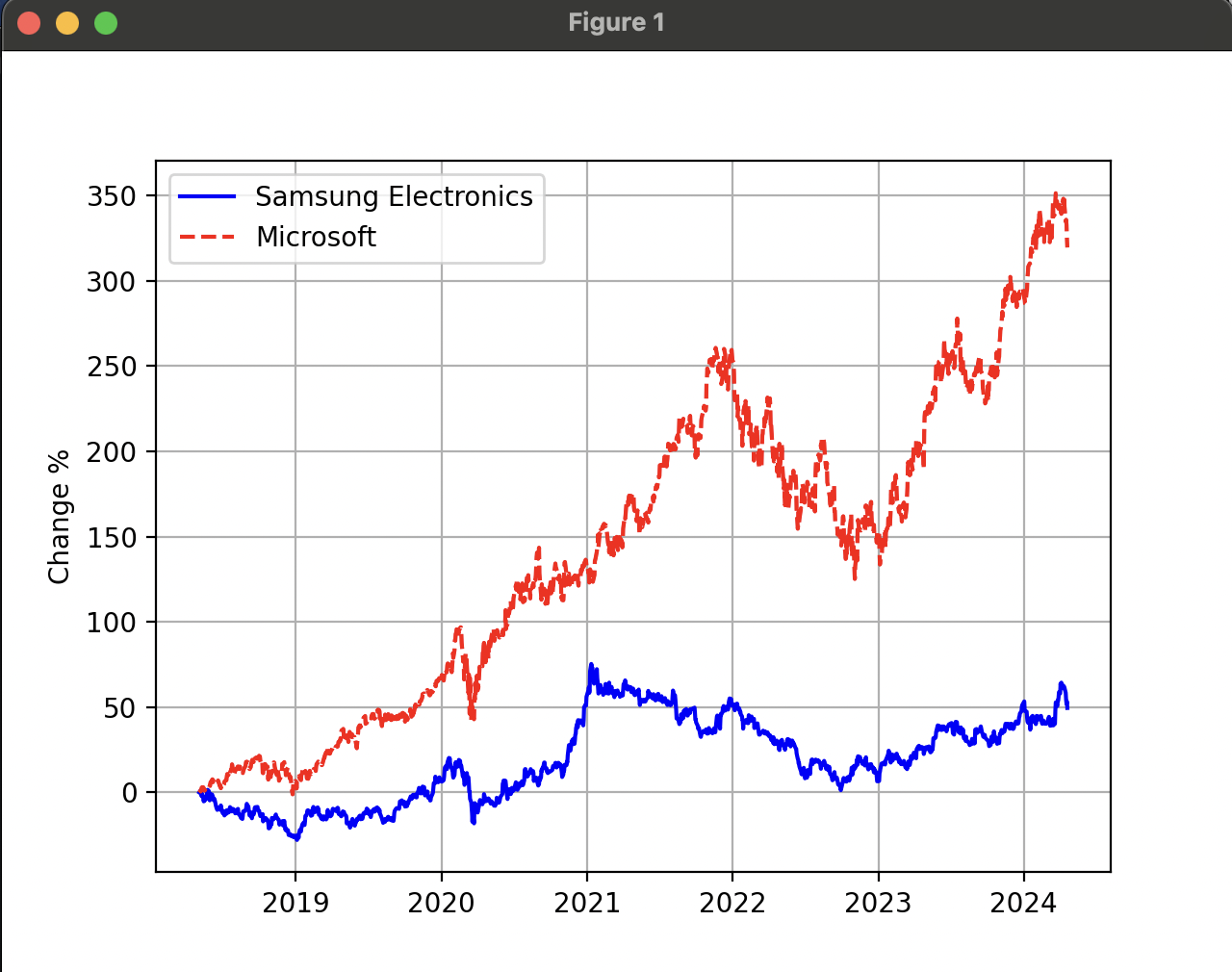
종목별로 전체적인 변동률을 비교해보려면, 일간 변동률의 누적곱을 계산해야 한다. 누적곱은 Series의 cumprod() 함수를 사용하여 계산할 수 있다.
- 삼성전자와 마이크로소프트의 주식수익률 비교
최대 손실 낙폭 (MDD)
최대 손실 낙폭(MDD, Maximum Drawdown)은 특정 기간 동안 포트폴리오의 최대 손실을 의미한다. MDD는 투자자가 투자한 자금 중 얼마나 많은 금액을 잃을 수 있는지를 나타내는 지표이다.
퀀트 투자에서는 수익률을 높이는 것보다 MDD를 낮추는 것이 더 낫다고 한다.
MDD를 계산하려면 Series에서 제공하는 rolling() 함수를 알아야 한다. rolling() 함수는 Series에서 윈도우 크기에 해당하는 개수만큼 데이터를 추출하여 집계 함수를 적용한다. 집계 함수는 min(), max(), mean() 등을 사용할 수 있다.
Series.rolling(윈도우 크기[, min_periods=1] [.집계 함수()])
아래의 예제는 야후 파이낸스에서 서브프라임 금융위기가 발생하기 이전부터 2024년 4월 23일(조회일 기준)까지의 KOSPI 지수 데이터를 다운로드하고 Rolling() 함수를 사용하여 1년 동안의 최대값과 최소값을 구하여 MDD를 계산한 예제이다.
- example code
- example result
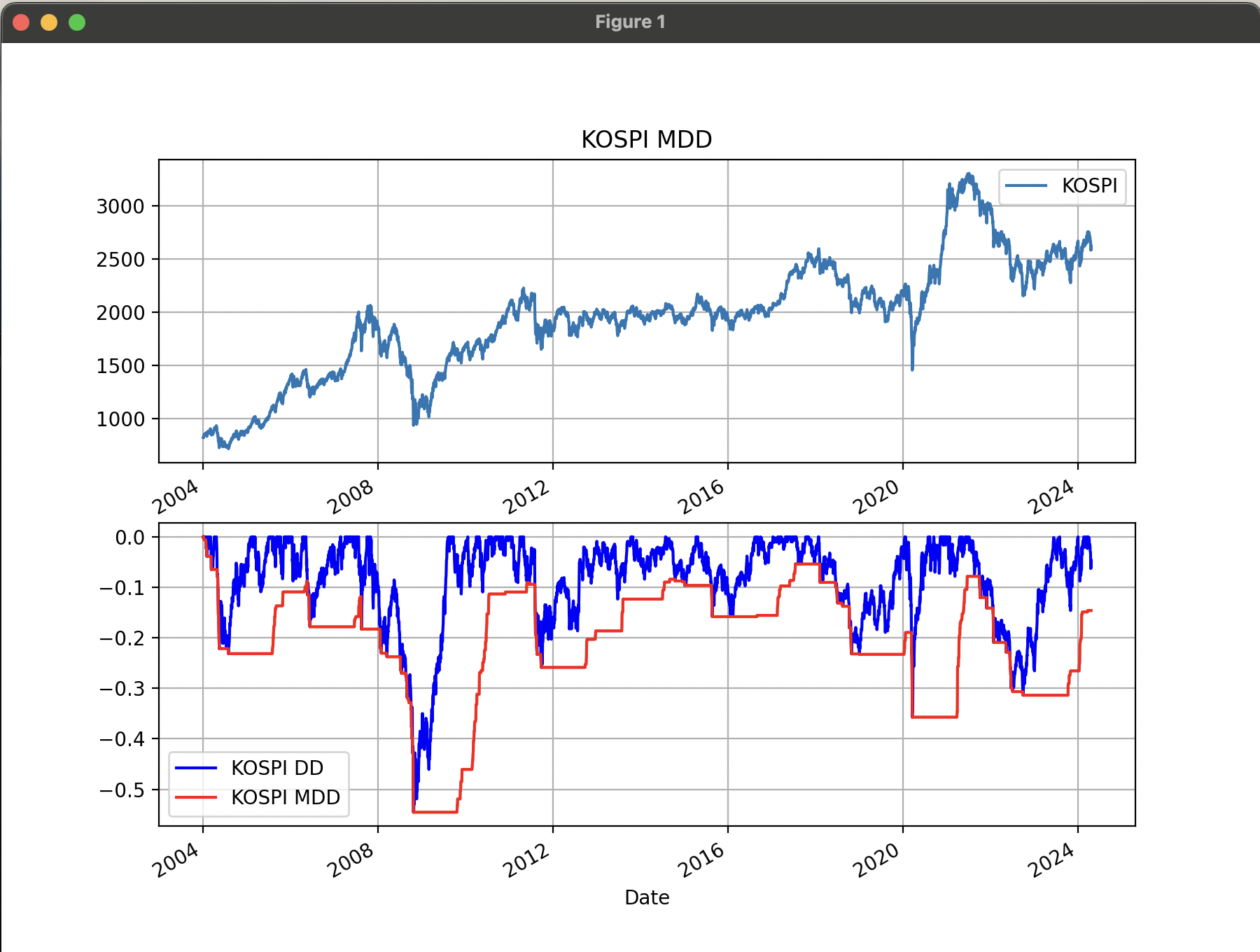
서브프라임 금융 위기 당시였던 2008년 10월 24일에 KOSPI 지수가 하락하면서 MDD도 마이너스를 기록했다.
그렇다면, MDD를 낮추려면 어떻게 해야할까?
Chat GPT에 물어보면 몇 가지 방법을 제시한다.
- 다양한 자산 분산: 포트폴리오에 다양한 자산을 포함하여 투자하면, 특정 자산의 급격한 하락이 포트폴리오 전체에 미치는 영향을 완화할 수 있다. 다양한 자산 유형에 투자하여 리스크를 분산시키는 것이 중요하다.
- 자산 재분배: 포트폴리오의 리밸런싱을 통해 리스크를 최적화할 수 있다. 정기적으로 자산을 재분배하여 MDD를 낮추고 투자 목표에 맞게 조정하는 것이 중요하다.
- 금융 파생상품 활용: 옵션, 선물 및 기타 파생상품을 활용하여 포트폴리오의 리스크를 헷지하거나 관리할 수 있다. 이러한 상품을 사용하여 포트폴리오의 특정 자산에 대한 손실을 상쇄하거나 제한할 수 있다.
- 자산 할당 재평가: 투자 목표와 리스크 허용 수준에 따라 포트폴리오의 자산 할당을 정기적으로 재평가하고 조정하는 것이 중요하다. 변화하는 시장 조건에 따라 적응하여 포트폴리오를 최적화하는 것이 중요하다.
- 시장 모니터링: 시장의 변화를 지속적으로 모니터링하고, 급격한 하락 추세를 조기에 감지하여 대응하는 것이 중요하다. 시장 상황을 신속하게 파악하고 적절한 조치를 취하여 포트폴리오의 손실을 최소화할 수 있다.
이러한 방법들을 조합하여 MDD를 최소화하는 데 도움이 된다고 한다.
투자자는 자신의 투자 목표, 리스크 허용 수준 및 시장 조건에 따라 적절한 전략을 선택할 수 있어야 한다.
MDD를 낮춰 효율적인 포트폴리오를 구성하기 위해서는 회귀 분석의 개념과 자산간의 상관관계에 대한 이해가 중요하다. 그 이유는 다음과 같다.
- 포트폴리오 최적화: 회귀 분석을 통해 자산간의 상관관계를 이해하고, 이를 기반으로 포트폴리오를 최적화할 수 있다. 상관관계가 낮은 자산을 조합하여 포트폴리오를 구성하면, 포트폴리오의 리스크를 분산시키고 MDD를 낮출 수 있다.
- 자산 할당 결정: 현대 포트폴리오 이론은 자산간의 상관관계를 고려하여 효율적인 자산 할당을 제안한다. 자산 간의 상관관계를 고려하여 포트폴리오의 자산 할당을 결정하면, 예상되는 수익과 리스크를 균형있게 조절할 수 있다.
- 헷지 및 리스크 관리: 상관관계가 높은 자산은 헷지나 리스크 관리에 활용될 수 있다. 회귀 분석을 통해 상관관계가 높은 자산을 식별하고, 이를 통해 리스크를 관리하거나 헷지할 수 있다.
- 투자 전략 개발: 자산간의 상관관계를 이해하고 회귀 분석을 통해 통찰력을 얻으면, 효과적인 투자 전략을 개발할 수 있다. 상관관계와 회귀 분석 결과를 바탕으로 투자 전략을 조정하면, MDD를 낮추고 수익을 극대화할 수 있다.
*헷지(hedging)는 투자 포트폴리오나 자산의 특정한 리스크를 완화하는 방법 중 하나이다. 주로 투자자들은 특정 자산이나 포트폴리오에 따른 미래의 불확실성을 줄이기 위해 헷지를 사용한다. 이는 특히 불확실한 시장 조건이나 예상치 못한 사건이 포트폴리오에 부정적인 영향을 줄 수 있는 경우에 중요하다.
이러한 이유로 다음은 회귀 분석의 개념과 자산간의 상관관계에 대한 이해를 해야한다.
회귀 분석과 상관 관계
회귀 분석은 데이터 간의 상관 관계를 분석하는 데 사용되는 통계 분석 방법이다. 회귀 분석에서는 회귀 모델을 설정한 후, 실제 관찰된 표본을 이용하여 회귀 모델의 계수를 측정한다. 독립변수라고 불리는 하나 이상의 변수와 종속변수라고 불리는 하나의 변수 사이의 관계를 나타내는 회귀식이 도출되면, 임의의 독립변수에 대한 종속변수의 값을 예측하는 것이 가능해진다. 이것을 예측(prediction)이라고 합니다.
아래의 예제에서는 야후 파이낸스에서 다우존스 지수와 KOSPI 지수 데이터를 다운로드하고, 종가(Close) 데이터만으로 두 지수를 단순히 비교하고, 이를 다시 지수화(indexation)하여 비교하는 그래프를 표현하는 예제이다.
- example code
- example result
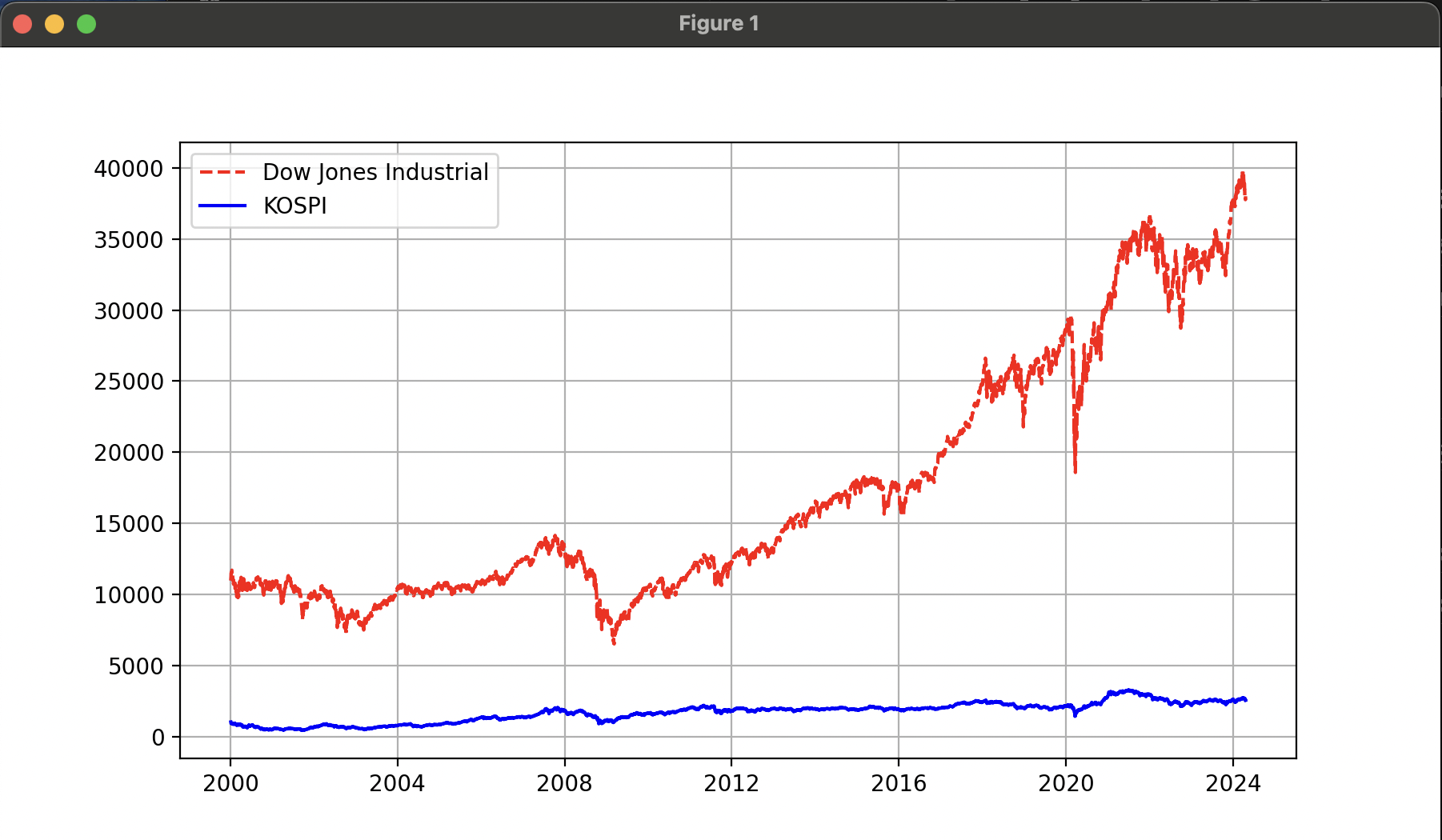
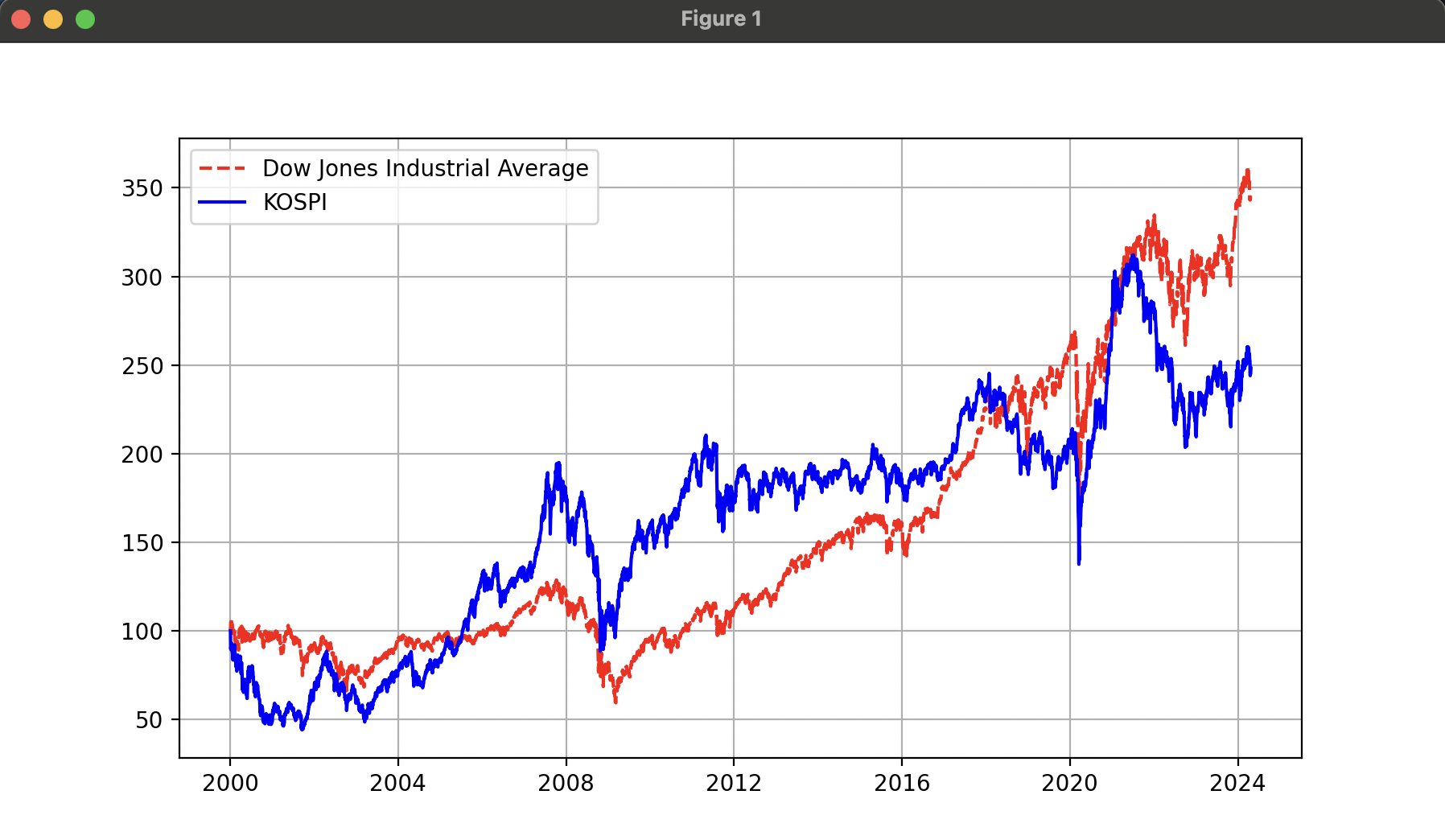
첫 번째 그래프에서는 지수 기준값이 서로 다르기 때문에 어느 지수가 더 좋은 성과를 냈는지 알아보기가 어려웠다. 지수화를 통해 2000년 1월 4일 종가 대비 일간 변동률을 계산하여 비교하면 각 지수별 상승률을 좀 더 쉽게 비교할 수 있게된다.
두 번째 그래프를 보면 두 지수의 상승률이 비슷한 것을 확인할 수 있다.
다음은 산점도 그래프를 활용한 분석 방법이다.
산점도란 두 변수 간의 관계를 시각적으로 표현하는 그래프이다. 산점도는 두 변수 간의 상관 관계를 파악하거나 두 변수 간의 패턴을 확인하는 데 유용하다.
아래의 예제에서는 가로축은 독립변수 x를 다우존스 지수로 설정하고, 세로축은 종속변수 y를 KOSPI 지수로 설정하여 산점도 그래프를 그리는 예제이다.
산점도 그래프를 그릴 때는 matplotlib.pyplot의 scatter() 함수를 사용한다.
두 지수의 데이터를 DataFrame으로 생성하고 scatter() 함수를 사용하여 그래프를 그릴 때 NaN 이슈가 발생하는데, 해결 방법에 대한 설명은 도서에서 자세히 참고할 수 있다. 아래는 예제 코드는 이러한 이슈를 모두 해결하여 산점도 그래프를 그리는 코드이다.
- example code
- example result
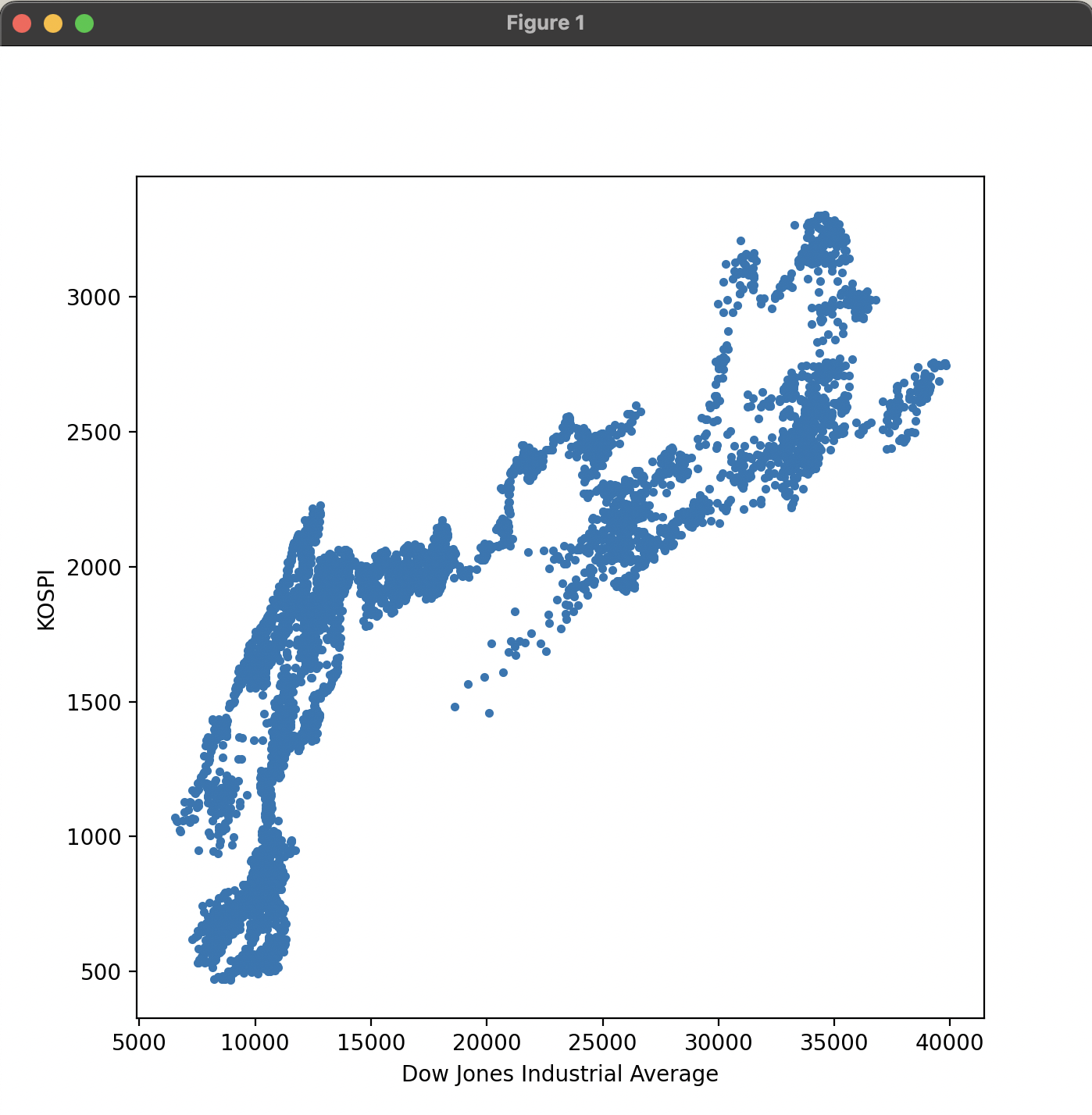
산점도의 점 분포가 y = x 선과 매우 유사하면 직접적인 관계가 있는 것으로 볼 수 있다. 다우존스 지수와 KOSPI 지수는 서로 어느 정도 영향력이 있기는 하지만 그다지 강하지는 않을 수 있다. 보다 정확한 분석을 위해 선형회귀분석 방법을 적용해 본다.
선형회귀분석을 위해 다음의 선형 회귀 모델을 활용해야 한다. 회귀 모델이란 연속적인 데이터 Y와 이 Y의 원인이 되는 X간의 관계를 나타내는 모델이다. 선형 회귀 모델은 다음과 같이 표현된다.

- Y : i번째 데이터 포인트에 대한 종속변수.
- X : i번째 데이터 포인트에 대한 독립변수.
- β0: X가 0일 때 Y 값을 나타내는 선형회귀모델의 절편(intercept).
- β1: 독립 변수 X의 계수로, X와 Y 사이 관계의 기울기(slope).
- ϵ: i번째 데이터 포인트와 연관된 오류 항으로, 관측된 Y 값과 해당 데이터 포인트에 대해 모델이 예측한 값 간의 차이.
- i: 데이터 세트의 각 개별 데이터 포인트를 나타내는 인덱스(1부터 n까지). 여기서 n은 총 데이터 포인트 수.
두 지수간의 선형 회귀 모델을 생성하기 위해 python scipy 라이브러리의 linregress() 함수를 사용한다. linregress() 함수는 두 변수 간의 선형 회귀 모델을 생성하고, 회귀 모델의 계수를 반환한다.
- example code
- example result
- slope=0.06481796952205979, # 기울기
- intercept=614.7935868733562, # y절편
- rvalue=0.8242328572280312, # r값 (상관계수)
- pvalue=0.0, # p값
- stderr=0.0005610275749123694, # 표준편차
- intercept_stderr=10.847180155384665) # y절편의 표준편차
위의 결과로부터 생성된 모델을 사용하여 선형 회귀 방정식을 확인할 수 있다. 기울기(slope)가 약 0.06이고 절편이 약 614.79인 경우, Y의 기대값은 614.79 + 0.06 * x로 표현될 수 있다. 임의의 x 값이 주어지면 해당 y 값을 예측할 수 있다.
상관계수에 따른 리스크 완화
위의 결과 중 r값 (상관계수)에 대해 알아보자. 상관계수는 독립변수와 종속변수 간의 선형 관계의 강도를 나타내는 지표이다. 상관계수는 -1에서 1 사이의 값을 가지며, 1에 가까울수록 강한 양의 선형 관계를, -1에 가까울수록 강한 음의 선형 관계를 나타낸다. 0에 가까울수록 두 변수 간의 선형 관계가 없다는 것을 의미한다.
두 자산의 상관계수가 1에 가까울수룩 두 자산은 함께 상승한다는 것을 의미한다. 반면, 상관계수가 -1에 가까울수록 두 자산은 함께 하락한다는 것을 의미한다. 상관계수가 0에 가까울수록 두 자산은 서로 독립적이다.
아래의 예제는 다우존스 지수와 KOSPI 지수의 산점도 분포와 선형 회귀 모델을 활용하여 회귀선을 그려서 상관계수를 계산하는 예제이다.
- example code
- example result
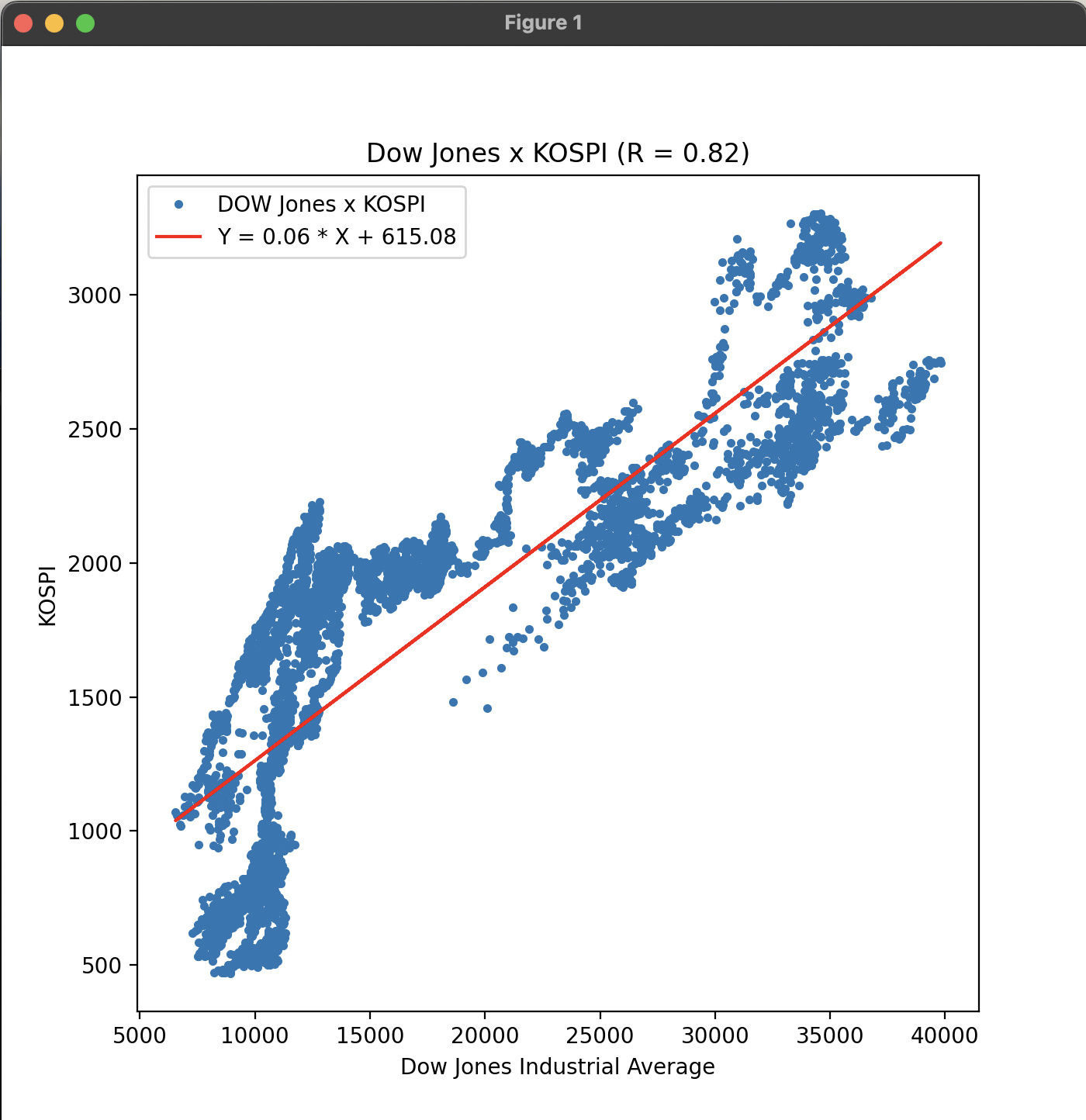
위의 그래프에서는 다우존스 지수와 KOSPI 지수의 상관계수가 약 0.82로 나타났다. 이는 두 지수 간에 강한 양의 선형 관계가 있음을 의미한다. 따라서, 두 지수는 함께 상승하거나 하락할 가능성이 높다.
같은 방법으로 미국 국채(TLT) 지수와 KOSPI 지수의 산점도 회귀선을 그려보는 예제를 살펴보자.
- example code
- example result
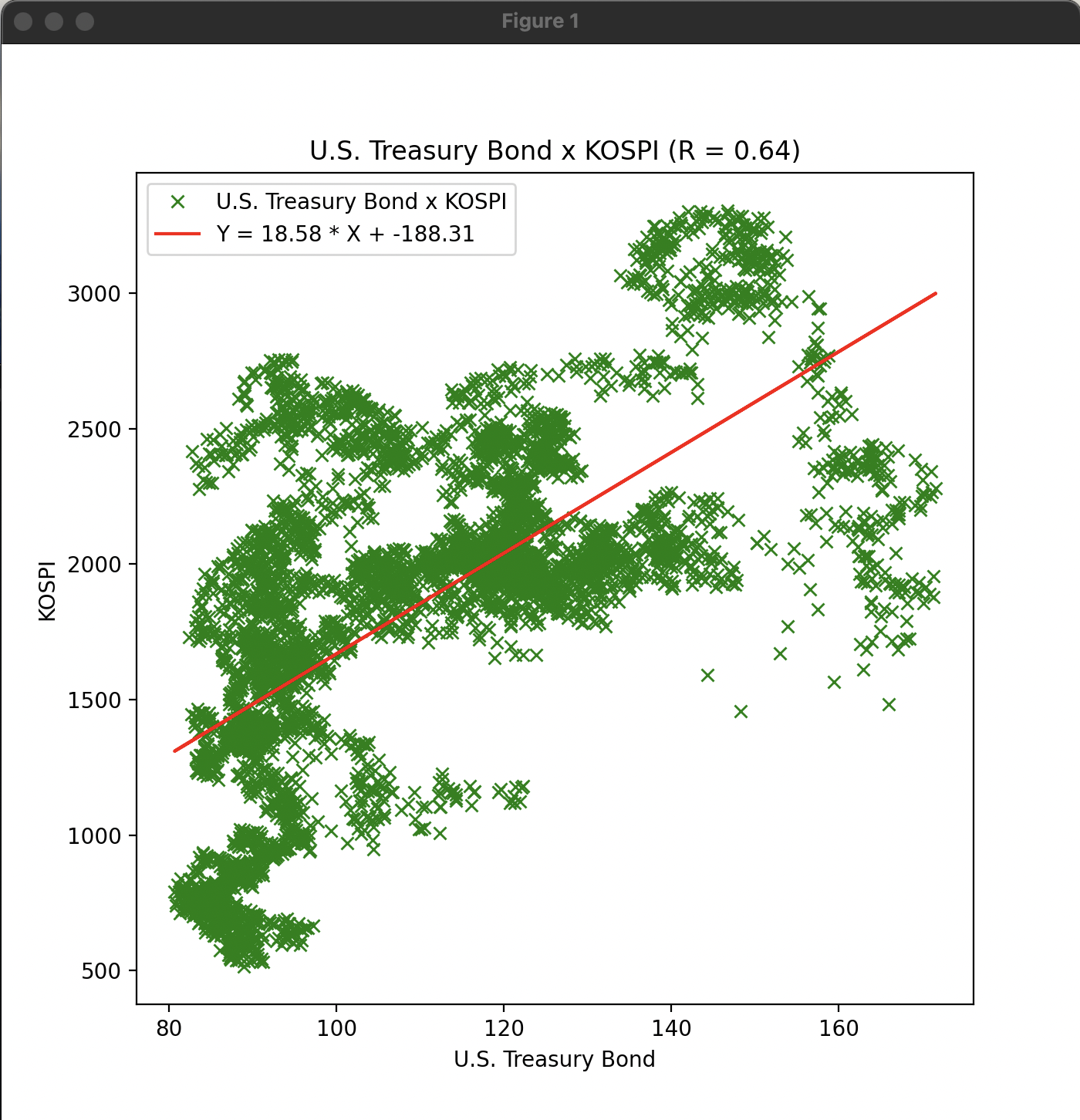
위의 그래프에서는 미국 국채(TLT) 지수와 KOSPI 지수의 상관계수가 약 0.64로 나타났다. 이는 미국 국채(TLT) 지수와 KOSPI 지수 간에 어느 정도 양의 선형 관계가 있음을 의미한다.
위의 2개의 예제를 통해 상관계수를 계산하고, 산점도 그래프와 선형 회귀 모델을 통해 두 자산 간의 관계를 시각적으로 확인할 수 있다. 상관계수를 통해 두 자산 간의 선형 관계의 강도를 파악하고, 이를 통해 리스크를 완화하는 효과를 얻을 수 있다.
만약 국내 주식에 이미 투자를 하고 있다면 다우존스 지수에 분산투자 하는 것보다 미국 채권에 분산 투자하는 것이 리스크 완화에 도움이 된다는 결론을 얻을 수 있다.
마치며
여기까지 파이썬 증권 데이터 분석 도서를 참고하여 NumPy와 Pandas를 활용하여 데이터 분석을 실습하고 야후 파이낸스 API를 통해 주식 데이터를 불러오고 Pandas를 사용하여 데이터를 가공하고 분석하는 방법을 살펴보았다. 또한, 회귀 분석과 상관계수를 활용하여 두 자산 간의 관계를 분석하고, 리스크를 완화하는 방법에 대해 살펴보았다.
도서의 내용이 2020년 출판을 기준으로 작성되어 예제를 구현하고 실습하는데, 현재 시점(2024년 4월)에서는 약간의 구현 방식에 차이가 있었지만 큰 이슈를 발생하지 않았다. 4년 정도의 기간이 지난만큼 데이터의 변화도 예제와는 조금 다른 점을 발견할 수 있었지만, 흐름을 이해하고 개념을 익히는 데 큰 어려움은 없었다. 대학생 시절에 배웠던 통계학과 회귀분석, 상관계수 등의 개념을 다시 상기시키는 계기가 되었고, 주식 데이터를 활용하여 데이터 분석을 실습해볼 수 있어서 좋은 인사이트를 얻을 수 있었다.
Chapter 4 미리보기
Chapter 4에서는 웹 스크래핑을 사용한 데이터 분석에 대한 내용을 다루는 것 같다. pandas 라이브러리를 활용하고, 엑셀 파일과 html을 활용하여 OHLC와 캔들 차트에 대해 알아보고 mplfinance 라이브러리를 활용한 차트를 그려본다.
포스팅의 피드백은 cremazer@gmail.com으로 보내주시면 포스팅을 작성하는데 반영하도록 하겠습니다.
참고 도서
참고 사이트
- Pandas Tutorial (YouTube)
- 현대 포트폴리오 이론(MPT)
“이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.”