퀀트 투자 자동매매 플랫폼 구축 - 증권 시세 DB 구축 및 조회 API 개발 (6)
이번 Chapter 5에서는 주기적으로 종목별 OHLC 데이터를 스크래핑해서 데이터베이스에 저장해두고, 필요할 때마다 조회할 수 있도록 데이터베이스를 구축하고, 시세를 조회하는 API를 구현하는 과정에 대해 알아봅니다.
1. 데이터베이스 구축
데이터베이스를 구축하기 위해 도서에서는 마리아DB를 사용하고 있습니다. 마리아DB는 MySQL과 호환되는 오픈소스 관계형 데이터베이스 관리 시스템(RDBMS)입니다.
저는 이미 MySQL을 사용하고 있어서 MySQL을 사용하여 데이터베이스를 구축하겠습니다. 마리아 DB를 사용하고 싶으신 분은 마리아DB 다운로드 페이지에서 다운로드 받으시고 설치하시면 됩니다.
- 데이터베이스 생성하기
데이터베이스를 생성하기 위해 DB 접속툴(MySQL Workbench 또는 DBeaver)를 실행하고, 새로운 스키마를 생성합니다.
또는 설치한 DB 서버에 접속하여 아래의 명령어를 입력하여 생성할 수 있습니다.
1
CREATE DATABASE investor;
이제 생성한 데이터베이스에 회사명과 종목코드를 저장할 company_info 테이블과 주식 시세를 저장할 stock_price 테이블을 생성합니다.
- 테이블 생성하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
CREATE TABLE companies
(
id INT AUTO_INCREMENT PRIMARY KEY NOT NULL COMMENT 'ID',
name VARCHAR(100) NOT NULL COMMENT '회사명',
stock_code CHAR(6) UNIQUE NOT NULL COMMENT '종목코드',
industry VARCHAR(100) NOT NULL COMMENT '업종',
main_product VARCHAR(255) COMMENT '주요제품',
listing_date DATE COMMENT '상장일',
fiscal_month VARCHAR(10) COMMENT '결산월',
ceo_name VARCHAR(100) COMMENT '대표자명',
website VARCHAR(255) COMMENT '홈페이지 url',
region VARCHAR(100) COMMENT '지역',
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '최종 업데이트 시간'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4 COMMENT ='상장 회사 정보';
-- 종목 코드 인덱스 추가
CREATE INDEX idx_stock_code ON companies(stock_code);
CREATE TABLE stock_prices
(
stock_code CHAR(6) NOT NULL COMMENT '종목코드', -- 삼성증권 종목 코드
trading_date DATE NOT NULL COMMENT '거래 날짜', -- 거래 날짜
open DECIMAL(10, 2) NOT NULL COMMENT '시가',
high DECIMAL(10, 2) NOT NULL COMMENT '고가',
low DECIMAL(10, 2) NOT NULL COMMENT '저가',
close DECIMAL(10, 2) NOT NULL COMMENT '종가',
volume BIGINT UNSIGNED NOT NULL COMMENT '거래량',
updated_at DATETIME COMMENT '최종 업데이트 날짜',
-- 기본 키 설정 (stock_code와 trading_date를 복합 기본 키로 사용)
PRIMARY KEY (stock_code, trading_date)
) ENGINE=InnoDB
PARTITION BY RANGE (YEAR(trading_date)) -- trading_date 기준으로 연도별 파티셔닝
(
PARTITION p1996 VALUES LESS THAN (1997),
PARTITION p1997 VALUES LESS THAN (1998),
PARTITION p1998 VALUES LESS THAN (1999),
PARTITION p1999 VALUES LESS THAN (2000),
PARTITION p2000 VALUES LESS THAN (2001),
PARTITION p2001 VALUES LESS THAN (2002),
PARTITION p2002 VALUES LESS THAN (2003),
PARTITION p2003 VALUES LESS THAN (2004),
PARTITION p2004 VALUES LESS THAN (2005),
PARTITION p2005 VALUES LESS THAN (2006),
PARTITION p2006 VALUES LESS THAN (2007),
PARTITION p2007 VALUES LESS THAN (2008),
PARTITION p2008 VALUES LESS THAN (2009),
PARTITION p2009 VALUES LESS THAN (2010),
PARTITION p2010 VALUES LESS THAN (2011),
PARTITION p2011 VALUES LESS THAN (2012),
PARTITION p2012 VALUES LESS THAN (2013),
PARTITION p2013 VALUES LESS THAN (2014),
PARTITION p2014 VALUES LESS THAN (2015),
PARTITION p2015 VALUES LESS THAN (2016),
PARTITION p2016 VALUES LESS THAN (2017),
PARTITION p2017 VALUES LESS THAN (2018),
PARTITION p2018 VALUES LESS THAN (2019),
PARTITION p2019 VALUES LESS THAN (2020),
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024),
PARTITION p2024 VALUES LESS THAN (2025)
);
-- 거래 날짜와 종목코드를 포함한 인덱스 추가
CREATE INDEX idx_stock_code_date ON stock_prices(stock_code, trading_date);
-- 테이블 설명 추가
ALTER TABLE stock_prices COMMENT = '주식 시세';
CREATE TABLE scraping_results
(
stock_code CHAR(6) NOT NULL COMMENT '종목코드',
last_trading_date DATE NOT NULL COMMENT '마지막 거래 날짜',
scraping_status VARCHAR(20) DEFAULT 'READY' COMMENT '스크래핑 처리 준비 상태 (예: READY, PROCESSING, COMPLETED, TERMINATED)',
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '업데이트 날짜',
PRIMARY KEY (stock_code, last_trading_date)
) COMMENT = '스크래핑 처리 결과 테이블';
주식 시세 테이블은 향후 계속해서 적재할 경우 데이터는 계속 증가할 것이므로 연도별로 파티셔닝을 설정하였습니다.
각 파티션은 연도별로 데이터를 관리하며, 특정 연도의 데이터를 조회할 때 성능을 높일 수 있습니다.
단, 파티셔닝으로 테이블을 구성할 때는 테이블 간의 제약조건을 설정할 수 없으므로, 테이블 간의 제약조건을 설정할 수 없는 경우에는 테이블 간의 제약조건을 설정할 수 있는 뷰를 생성하여 사용하거나, 파티션 테이블을 사용하지 않고 테이블을 별도로 생성하여 사용하는 방법을 고려해야 합니다.
- 종목코드의 거래일자의 시세 조회 예시
1
2
3
4
SELECT sp.*
FROM stock_prices sp
WHERE sp.stock_code = '005930'
AND sp.trading_date = '2024-09-29';
새로운 연도에 대한 파티션 추가
데이터를 적재할 때 파티셔닝을 새로 추가해야 할 경우가 발생한다면 아래의 명령어를 사용하여 파티션을 추가할 수 있습니다.
1
2
ALTER TABLE stock_prices
ADD PARTITION (PARTITION p2025 VALUES LESS THAN (2026));
2. 전체 일별 시세 데이터 저장 설계 및 구현
데이터베이스에 스크래핑한 종목코드의 시세 데이터를 저장하기 위해서는 아래와 같이 큰 맥락으로 구성할 수 있습니다.
- 데이터베이스에 저장할 상장 목록 데이터를 스크래핑한다.
- 상장 목록 데이터를 회사 정보 테이블에 저장한다.
- 만약 회사 정보가 이미 등록되어 있다면 회사 정보를 업데이트한다.
- 상장된 회사별로 주식 시세 데이터를 스크래핑한다.
- 주식 시세 데이터를 주식 시세 테이블에 저장한다.
- 만약 주식 시세 데이터가 이미 등록되어 있다면 주식 시세 데이터를 업데이트한다.
1번부터 3번까지의 과정에서는 상장된 회사의 정보를 저장하고, 4번부터 6번까지의 과정에서는 주식 시세 데이터를 저장합니다.
구현에 필요한 python 라이브러리 설치
1
pip install sqlalchemy beautifulsoup4 requests pytz cryptography
전체 일별 시세 데이터를 저장하는 구현 코드
아래의 깃헙 코드를 참고하여 전체 일별 시세 데이터를 저장하는 코드를 확인할 수 있습니다.
코드 내용 중 데이터베이스 비밀번호에 대한 설정은 파일을 읽어서 처리하도록 하였습니다. 이는 보안상의 이유로 코드에 비밀번호를 직접 입력하는 것을 피하기 위함입니다.
굳이 파일을 읽어서 처리하지 않고 코드에 비밀번호를 입력하고 싶다면 비밀번호를 코드에 직접 설정하여 실행해도 됩니다.
객체지향 프로그래밍 관점에서의 구조 및 클래스 설계
코드는 객체지향 설계를 통해 회사 정보와 주식 시세 데이터의 스크래핑 및 데이터베이스 저장 작업을 효율적으로 처리할 수 있도록 클래스를 정의하고 있습니다. 각각의 클래스는 특정한 역할과 책임을 가지며, 코드의 유지보수성과 확장성을 높이는 구조를 가지고 있습니다. 다음은 주요 클래스와 설계 관점에서의 설명입니다.
Company클래스 (SQLAlchemy 모델)
- 역할:
companies테이블과 매핑되는 데이터베이스 모델 클래스입니다. - 설명: 이 클래스는 상장된 회사 정보를 나타냅니다. SQLAlchemy의 Base 클래스를 상속받아 테이블 구조를 정의하고 있으며, 회사의 이름, 종목 코드, 업종 등 주요 정보를 포함하고 있습니다.
__repr__메서드를 통해 객체를 출력할 때 보기 쉽게 나타낼 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Company(Base):
__tablename__ = 'companies'
# 테이블 구조 정의
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(100), nullable=False) # 회사명
stock_code = Column(String(10), unique=True, nullable=False) # 종목코드
industry = Column(String(100), nullable=False) # 업종
main_product = Column(String(255)) # 주요 제품
listing_date = Column(Date) # 상장일
fiscal_month = Column(String(10)) # 결산월
ceo_name = Column(String(100)) # 대표자명
website = Column(String(255)) # 홈페이지
region = Column(String(100)) # 지역
updated_at = Column(DateTime, default=lambda: datetime.now(ZoneInfo('Asia/Seoul'))) # KST로 설정
def __repr__(self):
return f"<Company(name={self.name}, stock_code={self.stock_code})>"
StockPrice클래스 (SQLAlchemy 모델)
- 역할:
stock_prices테이블과 매핑되어 주식의 시세 데이터를 저장하는 클래스입니다. - 설명: 종목 코드와 거래 날짜를 기본키로 하며, 주식의 시가, 고가, 저가, 종가, 거래량 등의 정보를 포함합니다. 이 클래스는 주식 시세 데이터를 스크래핑한 후 데이터베이스에 저장하기 위한 구조를 정의합니다.
1
2
3
4
5
6
7
8
9
10
11
class StockPrice(Base):
__tablename__ = 'stock_prices'
stock_code = Column(CHAR(6), primary_key=True, nullable=False) # 종목코드
trading_date = Column(Date, primary_key=True, nullable=False) # 거래 날짜
open = Column(DECIMAL(10, 2), nullable=False) # 시가
high = Column(DECIMAL(10, 2), nullable=False) # 고가
low = Column(DECIMAL(10, 2), nullable=False) # 저가
close = Column(DECIMAL(10, 2), nullable=False) # 종가
volume = Column(BigInteger, nullable=False) # 거래량
updated_at = Column(DateTime, default=lambda: datetime.now(ZoneInfo('Asia/Seoul'))) # 최종 업데이트 시간
ScrapingResult클래스 (SQLAlchemy 모델)
- 역할: 각 종목의 스크래핑 상태를 추적하는 테이블과 매핑된 클래스입니다.
- 설명: 스크래핑한 마지막 거래 날짜와 스크래핑 상태를 기록하여 중복 스크래핑을 방지하고 진행 상태를 관리합니다. 이를 통해 효율적인 스크래핑 작업을 할 수 있습니다.
1
2
3
4
5
6
7
class ScrapingResult(Base):
__tablename__ = 'scraping_results'
stock_code = Column(CHAR(6), primary_key=True, nullable=False) # 종목코드
last_trading_date = Column(Date, primary_key=True, nullable=False) # 마지막 거래 날짜
scraping_status = Column(String(20), default='READY', nullable=False) # 스크래핑 처리 상태
updated_at = Column(DateTime, default=lambda: datetime.now(ZoneInfo('Asia/Seoul')), onupdate=datetime.now) # 업데이트 날짜
NaverFinanceScraper클래스 (주식 시세 스크래핑)
- 역할: 네이버 금융에서 주식 시세 정보를 스크래핑하는 클래스입니다.
- 설명: 특정 종목 코드를 입력받아 해당 주식의 시세 페이지에서 데이터를 스크래핑합니다. 데이터는 Pandas의 DataFrame으로 변환되며, 백오프(backoff) 전략을 사용하여 요청 실패 시 재시도할 수 있는 로직을 포함하고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
class NaverFinanceScraper:
"""
Naver 금융 사이트에서 주식 시세 데이터를 스크래핑하는 클래스.
"""
def __init__(self, stock_code):
self.stock_code = stock_code
self.domain = 'https://finance.naver.com'
self.uri = f'/item/sise_day.nhn?code={self.stock_code}'
self.headers = {'User-agent': 'Mozilla/5.0'}
def fetch_page(self, page_number):
"""특정 페이지의 데이터를 가져오는 메서드"""
url = f"{self.domain}{self.uri}&page={page_number}"
response = requests.get(url, headers=self.headers).text
return pd.read_html(StringIO(response), header=0)[0] # HTML 데이터를 pandas DataFrame으로 변환
def get_total_pages(self):
"""종목코드의 총 페이지 수를 가져오는 메서드"""
url = f"{self.domain}{self.uri}&page=1"
response = requests.get(url, headers=self.headers).text
bs = BeautifulSoup(response, 'lxml')
class_pgrr = bs.find('td', class_='pgRR')
if class_pgrr is None:
# HTML 페이지 구조가 변경되었을 수 있으므로, 페이지 내용을 출력
print("페이지 정보를 찾을 수 없습니다. 페이지 내용을 확인하세요.")
print(bs.prettify()) # BeautifulSoup으로 파싱된 페이지 출력
raise ValueError("페이지 정보가 없습니다.")
total_pages = class_pgrr.a['href'].split('=')[-1]
return int(total_pages)
def get_stock_data(self, max_retries=5, backoff_factor=1):
"""
종목코드에 대한 모든 페이지의 시세 데이터를 스크래핑하여
pandas DataFrame으로 반환하는 메서드.
백오프(backoff) 전략을 적용하여 재시도 및 대기시간을 증가시킵니다.
"""
try:
total_pages = self.get_total_pages()
except ValueError:
logging.error(f"종목 코드 {self.stock_code} 페이지 정보를 가져올 수 없습니다.")
return pd.DataFrame()
df_list = []
for page in range(1, total_pages + 1):
retries = 0
while retries <= max_retries:
try:
df = self.fetch_page(page)
df_list.append(df)
print(f"{page}/{total_pages} 페이지 데이터 스크래핑 완료.")
break
except Exception as e:
retries += 1
sleep_time = backoff_factor * (2 ** retries)
logging.error(f"종목 {self.stock_code}, 페이지 {page}에서 오류 발생: {e}")
time.sleep(sleep_time)
if retries > max_retries:
logging.error(f"종목 {self.stock_code}, 페이지 {page} 재시도 실패.")
break
if df_list:
full_df = pd.concat(df_list, ignore_index=True).dropna()
return full_df
else:
return pd.DataFrame()
DatabaseHandler클래스 (데이터베이스 처리)
- 역할: SQLAlchemy를 사용하여 데이터베이스와 상호작용하는 클래스입니다.
- 설명: 회사 정보 및 주식 시세 데이터를 데이터베이스에 저장하거나 업데이트하는 메서드를 제공합니다. 또한 스크래핑 진행 상태를 추적하고 업데이트하는 기능을 포함하고 있습니다. 데이터베이스 연결과 세션 관리는 이 클래스에서 처리됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
class DatabaseHandler:
def __init__(self, db_url):
self.engine = create_engine(db_url)
Base.metadata.create_all(self.engine)
self.Session = sessionmaker(bind=self.engine)
def add_or_update_company(self, company_data):
"""
회사 정보를 추가하거나 이미 존재하면 업데이트하는 메서드
:param company_data: {'name': 회사명, 'stock_code': 종목코드, 'industry': 업종, 'main_product': 주요제품,
'listing_date': 상장일, 'fiscal_month': 결산월, 'ceo_name': 대표자명,
'website': 홈페이지, 'region': 지역}
"""
session = self.Session()
try:
# 회사 정보가 이미 있는지 확인 (종목 코드로 검색)
company = session.query(Company).filter_by(stock_code=company_data['stock_code']).first()
if company: # 이미 존재하면 업데이트
company.name = company_data['name']
company.industry = company_data['industry']
company.main_product = company_data.get('main_product')
company.listing_date = company_data.get('listing_date')
company.fiscal_month = company_data.get('fiscal_month')
company.ceo_name = company_data.get('ceo_name')
company.website = company_data.get('website')
company.region = company_data.get('region')
company.updated_at = datetime.now(ZoneInfo('Asia/Seoul')) # KST로 업데이트 시간 설정
print(f"업데이트된 회사: {company.name} ({company.stock_code})")
else: # 존재하지 않으면 새로 추가
new_company = Company(
name=company_data['name'],
stock_code=company_data['stock_code'],
industry=company_data['industry'],
main_product=company_data.get('main_product'),
listing_date=company_data.get('listing_date'),
fiscal_month=company_data.get('fiscal_month'),
ceo_name=company_data.get('ceo_name'),
website=company_data.get('website'),
region=company_data.get('region'),
updated_at=datetime.now(ZoneInfo('Asia/Seoul')) # KST로 설정
)
session.add(new_company)
print(f"추가된 회사: {new_company.name} ({new_company.stock_code})")
session.commit()
except Exception as e:
session.rollback()
print(f"에러 발생: {e}")
finally:
session.close()
def update_scraping_result(self, stock_code, last_trading_date, status='COMPLETED'):
"""
스크래핑 결과를 scraping_results 테이블에 업데이트하는 메서드.
스크래핑 성공/실패 여부와 마지막 거래 일자를 업데이트.
"""
session = self.Session()
try:
result = session.query(ScrapingResult).filter_by(stock_code=stock_code).first()
if result: # 이미 존재하면 업데이트
result.scraping_status = status
result.last_trading_date = last_trading_date
result.updated_at = datetime.now(ZoneInfo('Asia/Seoul'))
else: # 존재하지 않으면 새로 추가
new_result = ScrapingResult(
stock_code=stock_code,
last_trading_date=last_trading_date,
scraping_status=status,
updated_at=datetime.now(ZoneInfo('Asia/Seoul'))
)
session.add(new_result)
session.commit()
except Exception as e:
session.rollback()
print(f"에러 발생: {e}")
finally:
session.close()
def get_company_stock_codes(self):
"""상장된 모든 회사의 stock_code를 가져오는 메서드"""
session = self.Session()
try:
# SQL 쿼리를 text로 명시
result = session.execute(text("SELECT stock_code FROM companies")).fetchall()
return [row[0] for row in result]
except SQLAlchemyError as e:
print(f"에러 발생: {e}")
return []
finally:
session.close()
def is_scraping_completed(self, stock_code):
"""
특정 종목의 스크래핑 상태가 'COMPLETED'인지 확인.
:param stock_code: 종목 코드
:return: 마지막 거래 날짜와 상태가 COMPLETED이면 True 반환
"""
session = self.Session()
try:
result = session.query(ScrapingResult).filter_by(stock_code=stock_code).first()
if result and result.scraping_status == 'COMPLETED':
print(f"종목 코드 {stock_code}는 이미 스크래핑 완료 상태입니다. (마지막 거래일: {result.last_trading_date})")
return True
return False
except Exception as e:
print(f"스크래핑 상태 확인 중 에러 발생: {e}")
return False
finally:
session.close()
def add_or_update_stock_price(self, stock_data):
"""stock_prices 테이블에 시세 정보를 추가하거나 업데이트하는 메서드"""
session = self.Session()
try:
stock_price = StockPrice(
stock_code=stock_data['stock_code'],
trading_date=stock_data['trading_date'],
open=stock_data['open'],
high=stock_data['high'],
low=stock_data['low'],
close=stock_data['close'],
volume=stock_data['volume'],
updated_at=datetime.now(ZoneInfo('Asia/Seoul'))
)
session.merge(stock_price) # 기본키가 존재하면 업데이트, 없으면 추가
session.commit()
print(f"종목 {stock_data['stock_code']} - {stock_data['trading_date']} 시세 정보 저장 완료")
except SQLAlchemyError as e:
session.rollback()
print(f"에러 발생: {e}")
finally:
session.close()
CompanyScraper클래스 (상장 회사 목록 스크래핑)
- 역할: KRX(한국거래소) 웹사이트에서 상장된 회사 목록을 스크래핑하는 클래스입니다.
- 설명: KRX에서 제공하는 데이터를 Pandas로 처리하여 각 회사의 이름, 종목 코드, 업종 등을 추출한 후, 이를 데이터베이스에 저장할 수 있도록 리스트로 반환합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
class CompanyScraper:
def __init__(self, url):
self.url = url
def scrape(self):
"""
KRX에서 상장 회사 목록을 스크래핑하여 회사명과 종목코드를 반환
:return: [{'name': '삼성전자', 'stock_code': '005930', 'industry': 업종, 'main_product': 주요 제품,
'listing_date': 상장일, 'fiscal_month': 결산월, 'ceo_name': 대표자명, 'website': 홈페이지, 'region': 지역}]
"""
response = requests.get(self.url)
response.encoding = 'euc-kr' # 한글 인코딩을 맞춰줌
# pandas를 사용해 데이터를 스크래핑
tables = pd.read_html(StringIO(response.text))
# 첫 번째 테이블 선택
df = tables[0]
# '종목코드'를 숫자 형식으로 변환하고, 6자리 문자열로 포맷팅
df['종목코드'] = df['종목코드'].astype(int).map('{:06d}'.format)
# 필요한 열만 선택 (회사명, 종목코드, 업종, 주요제품, 상장일, 결산월, 대표자명, 홈페이지, 지역)
df = df[['회사명', '종목코드', '업종', '주요제품', '상장일', '결산월', '대표자명', '홈페이지', '지역']]
# 날짜 형식 변환
df['상장일'] = pd.to_datetime(df['상장일'], errors='coerce', format='%Y-%m-%d')
# NaN 값을 None으로 변환
df = df.where(pd.notnull(df), None)
# 데이터프레임을 리스트로 변환
company_list = df.to_dict('records')
# company_list의 각 딕셔너리는 {'name': '회사명', 'stock_code': '종목코드'} 형식
return [
{
'name': company['회사명'],
'stock_code': company['종목코드'],
'industry': company['업종'],
'main_product': company['주요제품'],
'listing_date': company['상장일'],
'fiscal_month': company['결산월'],
'ceo_name': company['대표자명'],
'website': company['홈페이지'],
'region': company['지역']
}
for company in company_list
]
StockScraper클래스 (시세 데이터 스크래핑 및 저장)
- 역할: 각 회사의 주식 시세 데이터를 스크래핑하고, 스크래핑된 데이터를 데이터베이스에 저장하는 역할을 담당하는 클래스입니다.
- 설명: 종목 코드를 입력받아
NaverFinanceScraper를 통해 데이터를 스크래핑하고, 스크래핑된 데이터를DatabaseHandler를 통해 데이터베이스에 저장합니다. 스크래핑 상태를 관리하기 위해 스크래핑 완료 후scraping_results테이블을 업데이트합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
class StockScraper:
"""
주식 스크래핑을 관리하는 클래스.
"""
def __init__(self, db_handler, stock_code):
self.stock_code = stock_code
self.db_handler = db_handler
self.scraper = NaverFinanceScraper(stock_code) # Naver 금융 스크래퍼 인스턴스
def scrape_and_save(self):
"""시세 데이터를 스크래핑하여 DB에 저장하는 메서드"""
print(f"종목 코드 {self.stock_code} 시세 데이터를 스크래핑 시작...")
stock_data_df = self.scraper.get_stock_data() # 백오프 전략 적용된 메서드 사용
# 스크래핑된 데이터가 없으면 다음 종목으로 넘어감
if stock_data_df.empty:
print(f"종목 코드 {self.stock_code}에서 데이터를 찾을 수 없습니다. 다음 종목으로 넘어갑니다.")
return # 데이터가 없으면 종료
# 스크래핑된 데이터의 열 이름 확인
print(stock_data_df.columns) # 열 이름을 확인
# 열 이름이 다를 경우 공백 제거 및 열 이름 맞춤
stock_data_df.columns = stock_data_df.columns.str.strip()
# '날짜' 열이 없거나 데이터가 없는 경우 종료
if '날짜' not in stock_data_df.columns:
print(f"종목 코드 {self.stock_code}에서 '날짜' 열을 찾을 수 없습니다. 다음 종목으로 넘어갑니다.")
return # '날짜' 열이 없으면 종료
# 필요한 데이터만 선택하고 각 row를 DB에 저장
stock_data_df = stock_data_df[['날짜', '종가', '시가', '고가', '저가', '거래량']].rename(
columns={'날짜': 'trading_date', '종가': 'close', '시가': 'open', '고가': 'high', '저가': 'low', '거래량': 'volume'})
stock_data_df['trading_date'] = pd.to_datetime(stock_data_df['trading_date'], format='%Y.%m.%d')
# 마지막 거래 날짜 저장을 위해 가장 최신 날짜를 찾음
last_trading_date = stock_data_df['trading_date'].max().date()
for _, row in stock_data_df.iterrows():
stock_data = {
'stock_code': self.stock_code,
'trading_date': row['trading_date'].date(),
'open': row['open'],
'high': row['high'],
'low': row['low'],
'close': row['close'],
'volume': int(row['volume'])
}
self.db_handler.add_or_update_stock_price(stock_data)
print(f"스크래핑 완료! 종목 코드 {self.stock_code}")
# 스크래핑 완료 후, scraping_results 테이블에 마지막 거래 일자를 업데이트
self.db_handler.update_scraping_result(self.stock_code, last_trading_date, status='COMPLETED')
3. 실행 및 테스트
위의 코드를 실행하여 1차적으로 전체 데이터를 스크래핑하고 데이터베이스에 저장하는 코드입니다.
초기 작성된 코드에서 수차례 테스트를 거치며 코드를 다듬어 완성된 초기 버전입니다.
도서에서는 20년도 기준으로 데이터를 조회하여 등록하는데 5시간 정도 걸렸다고 되어 있는데, 제가 실행했을 때는 데이터를 조회하고 등록하는데 적어도 12시간은 넘게 소요된 것 같습니다.
코드가 실행되는 중간에 데이터를 등록하지 못하는 오류도 발견되면 코드를 수정하고 다시 실행해야 합니다.
이미 등록한 코드는 다시 등록하지 않도록 스크래핑 결과를 저장하는 테이블을 이용하여 중복 등록을 방지하였습니다.
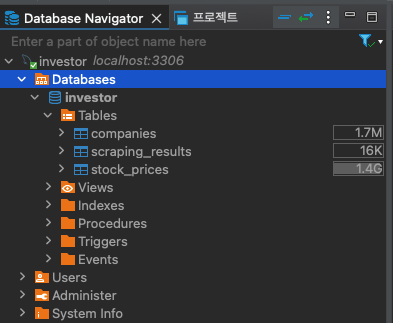
오랜 시간동안 초기 데이터 전체가 등록이 완료된 후 데이터를 확인해봤습니다.
(2024.10.01 기준)
- 등록된 상장 회사 수 : 2,719
- 등록된 주식 시세 데이터 수 : 9,933,157
- 저장공간 확인
삼성전자 주식 시세 확인
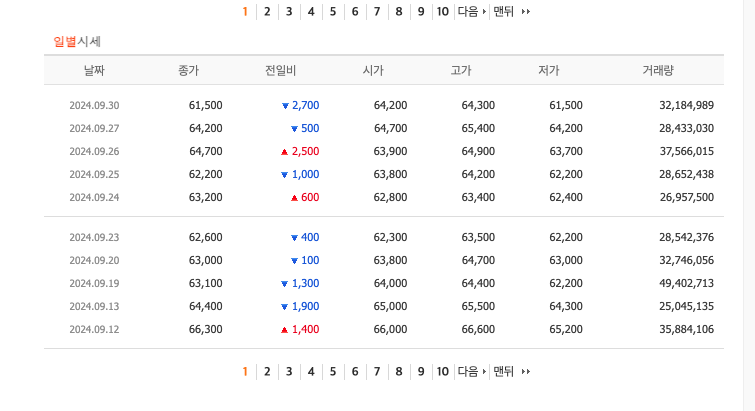
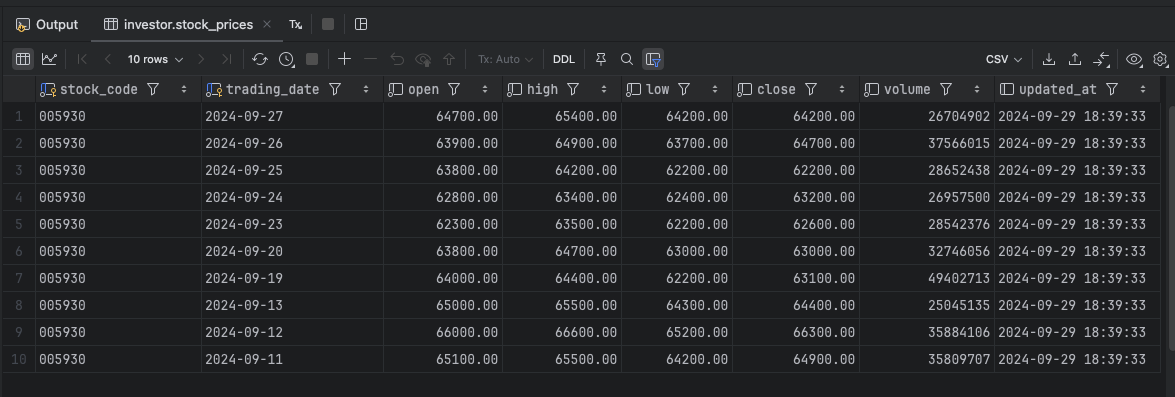
위의 그림과 같이 사이트에서 주식 시세는 9월 30일까지 조회됩니다.
그러나 데이터베이스에 저장된 주식 시세는 9월 29일까지만 등록되어 있습니다.
이제 특정일자의 주식 시세 데이터를 스크래핑하여 데이터베이스에 저장하는 코드를 작성하고 실행해보겠습니다.
4. 특정 일자의 주식 시세 데이터 스크래핑 및 저장하기
특정 일자의 주식 시세 데이터를 스크래핑 하기 위해 main 함수에서 상장 회사 목록 조회 이후 프로세르를 아래와 같이 변경했습니다.
- 스크래핑 결과를 준비 상태로 업데이트한다.
- 스크래핑 상태에 등록되어 있는지 확인한다.
- 스크래핑 상태에 등록되지 않은 경우 새로 스크래핑 처리를 시작한다. (신규 종목)
- 스크래핑 상태에 등록되어 있는 경우 특정 일자 이후로 스크래핑이 완료된 경우 건너뛴다.
- 최근 7일 간의 시세 데이터 확인한다.
- 최근 7일 간 데이터가 없으면 스크래핑 상태를 ‘종료’ 처리하고 다음 종목으로 넘어간다. (다음 스크래핑부터 이 종목코드는 스크래핑하지 않음)
- 종목코드, 특정 일자의 시세 데이터가 있는 경우 다음으로 넘어간다.
- 종목코드, 특정 일자의 시세 데이터가 없는 경우 스크래핑을 시작한다.
위의 프로세스가 구현된 최종 코드는 아래의 깃헙 코드를 확인하세요.
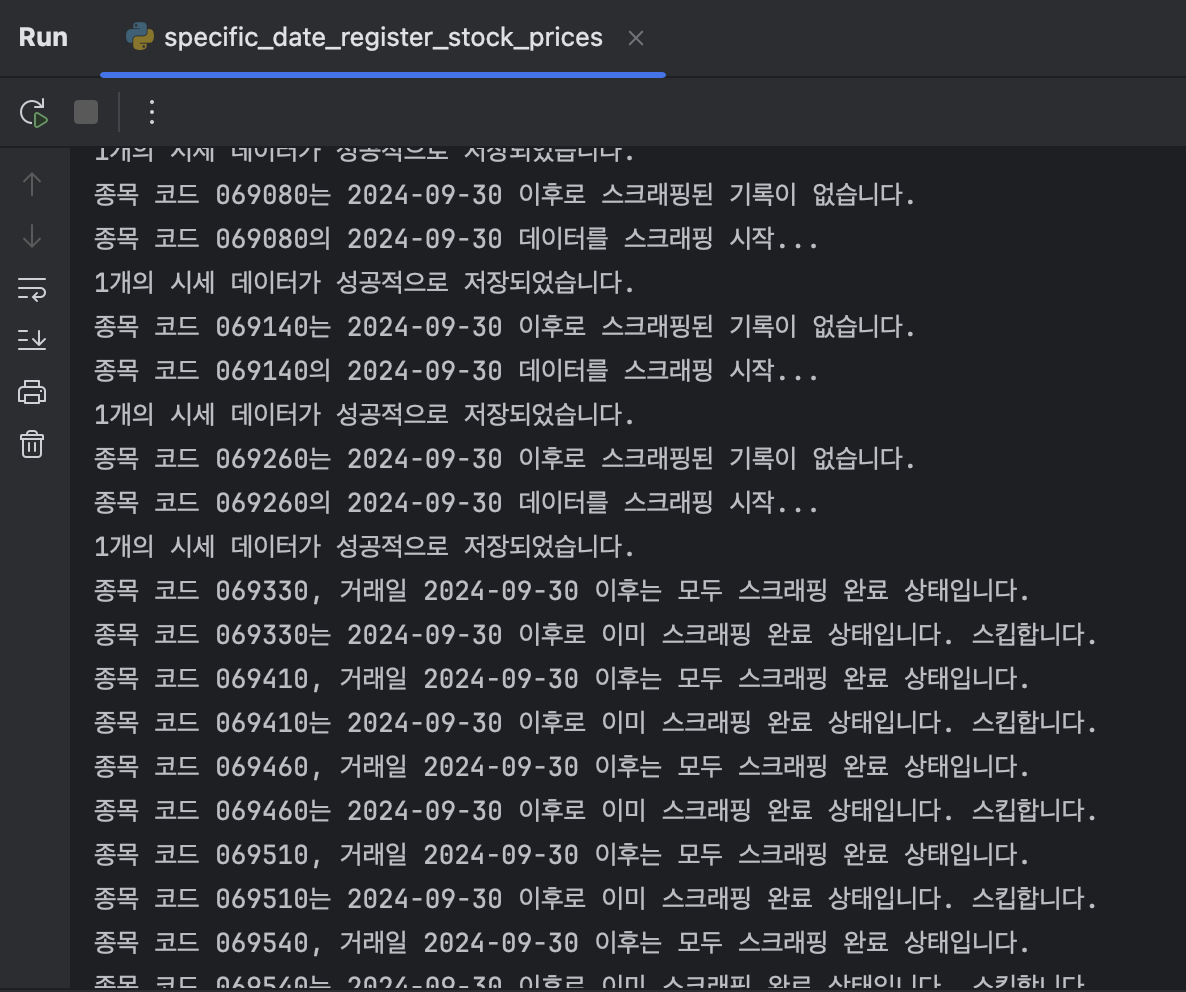
코드를 실행하면 아래의 그림과 같이 특정 일자(2024-09-30)의 주식 시세 데이터를 스크래핑하여 데이터베이스에 저장합니다.
스크래핑 기록이 없으면 데이터를 스크래핑하여 저장하고, 스크래핑 기록이 있으면 스크래핑을 건너뛰어 다음 종목으로 넘어갑니다.
5. 주식 시세 조회 API 개발
이제 지금까지 등록한 데이터를 조회할 수 있는 API를 개발해야 합니다. 도서에서는 API라고 하고지만, 코드의 구현 과정을 보니 주식 시세 데이터를 조회하는 함수를 개발하는 것이었습니다.
도서에서는 pymysql 라이브러리를 사용하여 데이터베이스에 접속하고 쿼리를 실행하는 방법을 설명하고 있습니다.
위에 예제 코드에서는 SQLAlchemy를 사용하여 데이터베이스에 접속하고 쿼리를 실행하는 방법을 사용하여 API 함수 또한 SQLAlchemy를 사용하여 개발하려고 합니다.
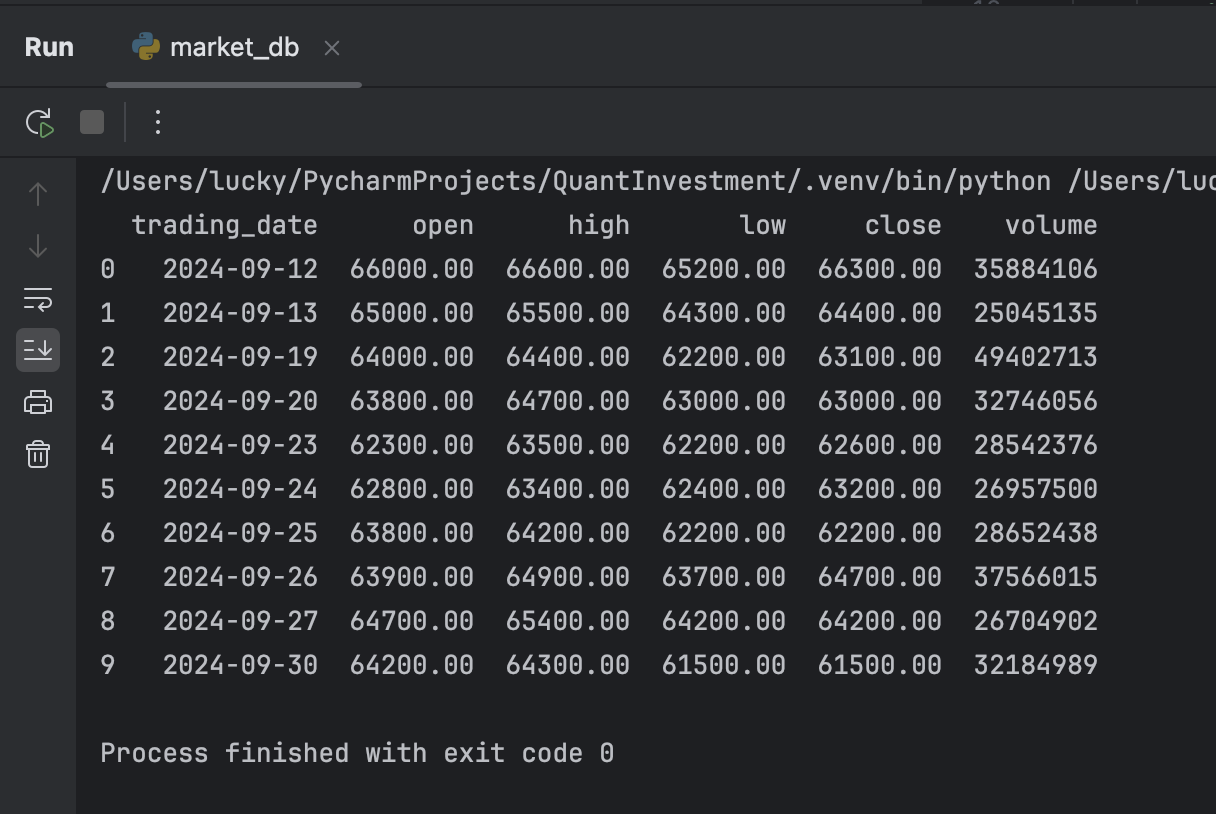
시세를 조회하는 클래스는 MarketDB 라는 클래스 명을 사용했습니다. 이 클래스는 한국거래소 종목코드에 해당하는 상장기업명을 찾아 주어진 기간동안 주식 시세 데이터를 조회하는 기능을 가지고 있습니다.
아래의 깃헙 코드를 참고하여 주식 시세 조회 API를 개발하는 코드를 확인할 수 있습니다.
실행결과
마치며
이번 포스팅에서는 데이터베이스에 상장 회사 정보와 주식 시세 데이터를 저장하는 과정을 진행해봤습니다.
도서에서 설명하고 있는 대부분의 내용을 위주로 진행했으며 코드를 실행하면서 오류가 발생하거나 데이터가 등록되지 않는 경우가 있어 코드를 수정하고 다시 실행하는 과정을 반복하였습니다.
데이터베이스를 연동하는 경우 pymysql을 사용할 수 있지만 최근 파이썬 블로그들에서 언급되고 있는 SQLAlchemy를 사용하는 경우가 많아서 이번 코드를 작성하면서 SQLAlchemy를 사용하여 데이터베이스에 연동하는 코드를 작성하였습니다.
확실히 라이브러리를 사용하는 것이 코드의 가독성과 유지보수성을 높여주는 것 같습니다. 뭐랄까 pymysql이 JDBC와 같은 느낌이라면 SQLAlchemy는 JPA와 같은 느낌이라고 할 수 있을 것 같습니다. :)
데이터베이스의 설치 과정과 pymysql을 사용하는 방법으로 구현해보고 싶은 분들은 본 프로젝트를 참고하고 있는 아래의 참고 도서를 참고하셔서 진행해보시면 좀 더 자세히 설명되어 있으므로 도움이 될 것 같습니다.
다음 포스팅에서는 트레이딩 전략과 구현에 대한 내용을 학습해보겠습니다.
포스팅의 피드백은 cremazer@gmail.com으로 보내주시면 포스팅을 작성하는데 반영하도록 하겠습니다.
참고 도서
참고 사이트
“이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.”