퀀트 투자 자동매매 플랫폼 구축 - 웹 스크래핑을 사용한 증권 데이터 수집 및 캔들 차트 활용 실습 (5)
이번 Chapter 4에서는 한국거래소에서 제공하는 상장법인 목록을 다운로드해서 국내 상장 기업 주식 종목코드를 구한 뒤, 네이버 금융(증권)에서 일자별 주가 데이터를 웹 스크래핑하고, 최종 수집한 주가 데이터를 캔들 차트로 그려봄으로써 인터넷에서 증권 데이터를 수집하여 분석하는 과정에 대해 알아봅니다.
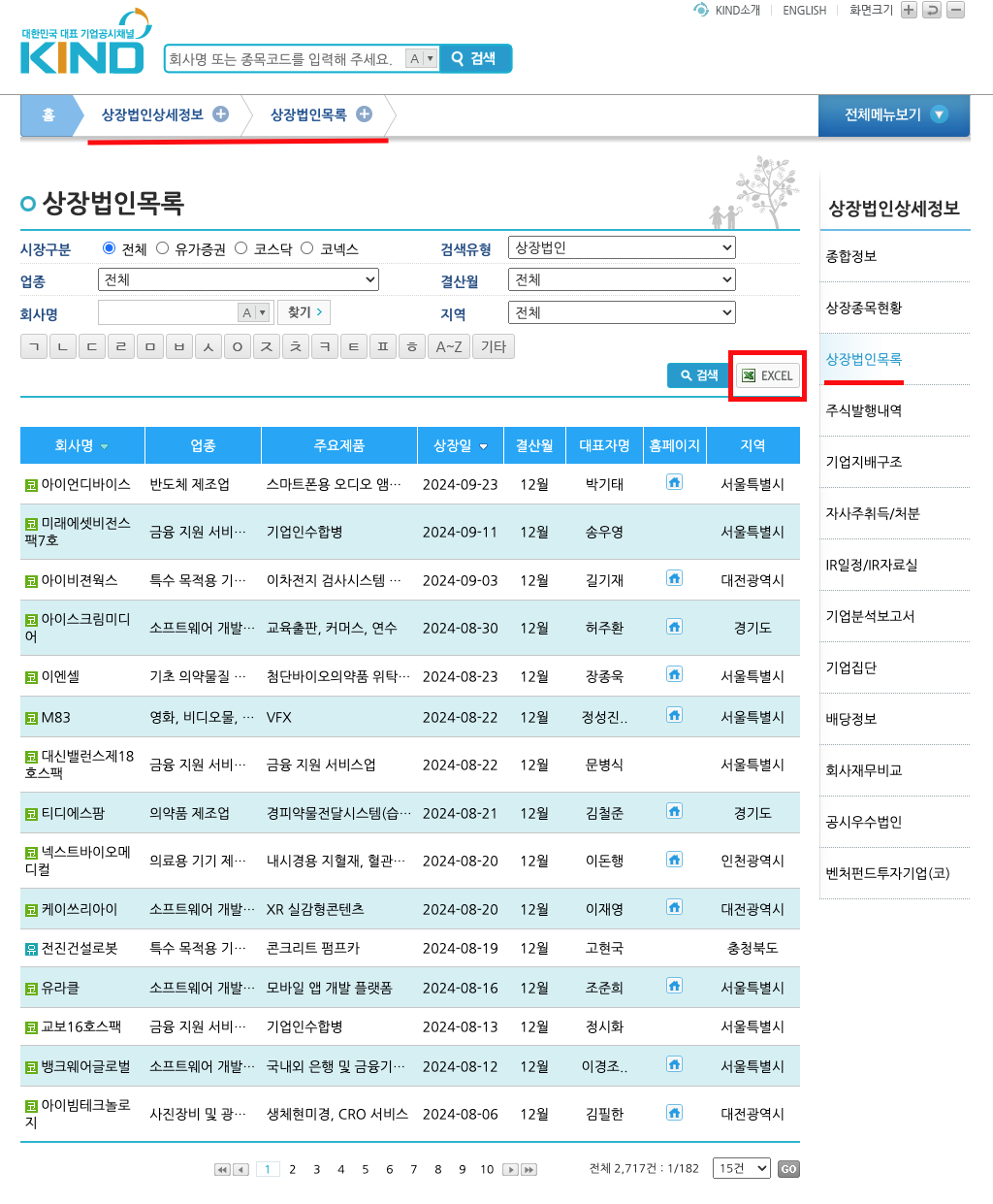
상장법인 목록 다운로드
상장법인 목록을 다운로드하려면 기업공시채널에 접속해서 상장법인상세정보 > 상장법인목록 화면에서 EXCEL 버튼을 클릭하여 다운로드합니다.
python으로 상장법인 목록 출력하기
목록을 출력하는 방법은 2가지가 있습니다. 첫 번째 방법은 pandas 라이브러리를 사용하여 엑셀 파일을 읽어오는 방법이고, 두 번째 방법은 다운로드 url을 사용하여 직접 데이터를 가져오는 방법입니다.
pandas 라이브러리를 사용하여 엑셀 파일 읽어오기
- 다운로드한 xls 파일을 읽어오는 방법은 아래의 코드를 실행하여 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
import pandas as pd
# Set the downloaded file path
xls_file_path = '/Users/lucky/Documents/quant/상장법인목록.xls'
# Read xls Excel File
krx_list = pd.read_html(xls_file_path)
# Print the first element of the list
print(krx_list[0])
- 실행결과
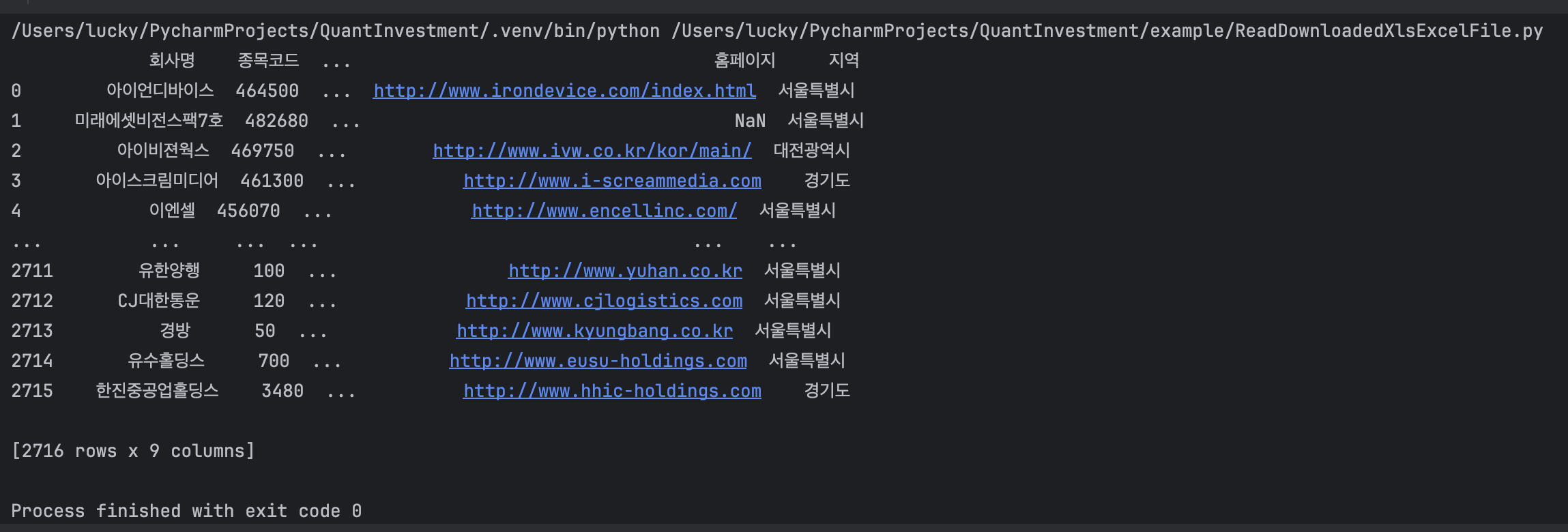
다운로드한 xls 파일은 html 태그로 구성되어 있어서 pandas 라이브러리의 read_html 함수를 사용하여 읽어올 수 있습니다.
엑셀파일인데 html인 이유는 엑셀 파일을 html로 변환하여 저장하도록 개발된 것이기 때문이라고 추측됩니다. 오래된 개발 방식의 산물인 듯 하네요.
- xls 파일은 xlsx 파일로 다시 저장하여 사용하면 아래의 코드와 같이 pandas 라이브러리의
read_excel함수를 사용하여 읽어올 수 있습니다.
1
2
3
4
5
6
7
import pandas as pd
xlsx_file_path = '/Users/lucky/Documents/quant/상장법인목록.xlsx'
krx_list = pd.read_excel(xlsx_file_path)
print(df.head(10))
- 실행결과
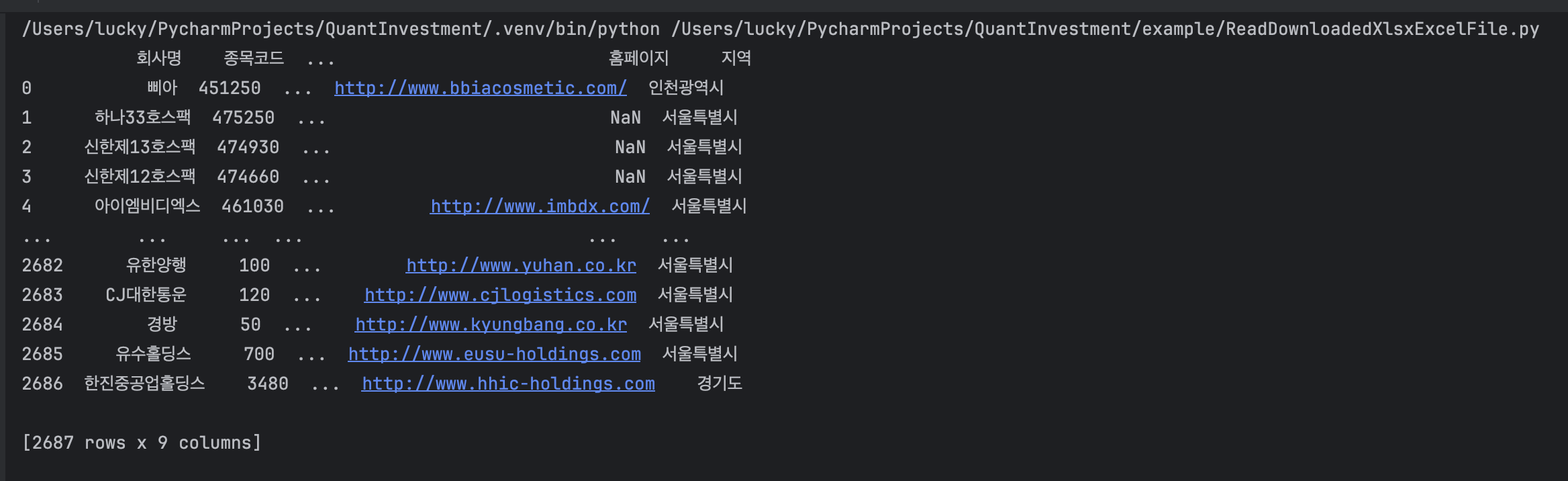
아래와 같은 오류가 발생하면 openpyxl 라이브러리를 설치하면 해결됩니다.
1
2
3
...
ModuleNotFoundError: No module named 'openpyxl'
...
- openpyxl 라이브러리 설치
1
pip install openpyxl
- 파일을 다운로드하지 않고 url을 통해 데이터를 가져오는 방법은 아래의 코드와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import pandas as pd
import requests
from io import StringIO
# URL 설정
url = 'http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13'
# requests로 데이터 가져오기
response = requests.get(url)
# 인코딩 설정 (예: 'EUC-KR'로 시도해볼 수 있음)
response.encoding = 'euc-kr' # 'euc-kr' 또는 'cp949' 같은 인코딩을 시도
# StringIO로 감싸서 pandas.read_html에 전달
tables = pd.read_html(StringIO(response.text))
print(tables[0])
- 실행결과
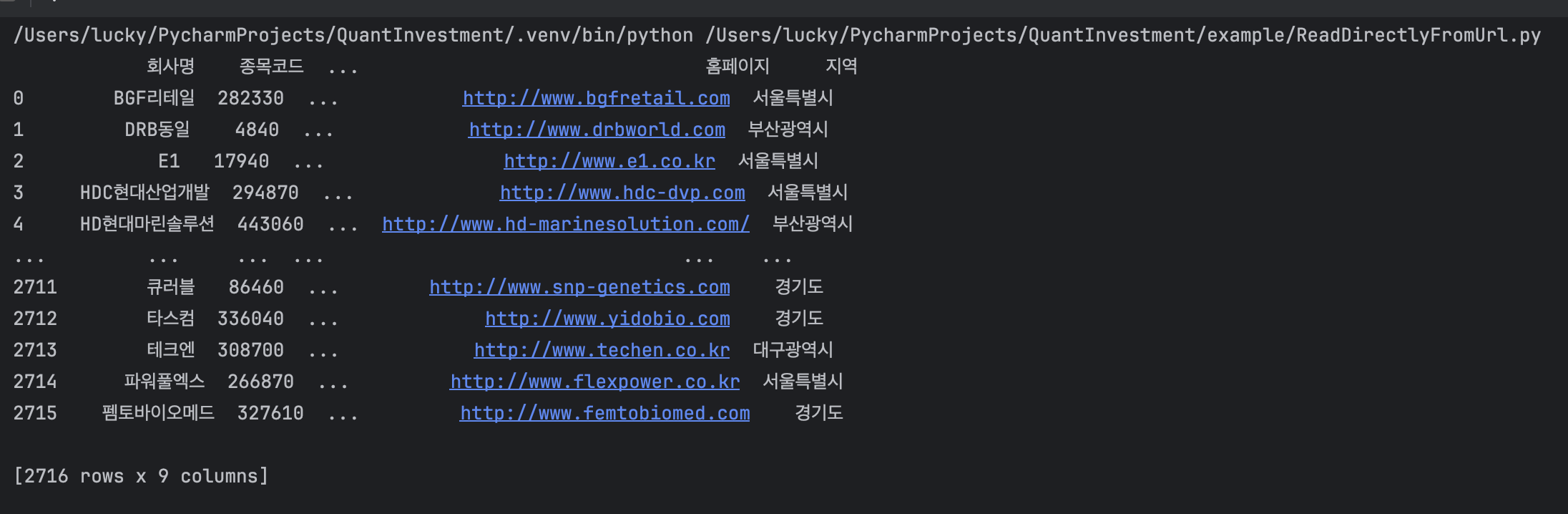
실행결과를 자세히 들여다보면 종목코드가 6자리가 아닌 숫자길이만큼 출력되는 것이 보입니다. 종목코드를 6자리로 맞추기 위해 아래와 같이 코드를 변경합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import pandas as pd
import requests
from io import StringIO
# URL 설정
url = 'http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13'
# requests로 데이터 가져오기
response = requests.get(url)
# 인코딩 설정 (예: 'EUC-KR'로 시도해볼 수 있음)
response.encoding = 'euc-kr' # 'euc-kr' 또는 'cp949' 같은 인코딩을 시도
# StringIO로 감싸서 pandas.read_html에 전달
tables = pd.read_html(StringIO(response.text))
# tables는 리스트이므로 첫 번째 테이블을 선택
df = tables[0]
# tables는 리스트이므로 첫 번째 테이블을 선택
df = tables[0]
# '종목코드'를 숫자 형식으로 변환하고, 6자리 문자열로 포맷팅
df['종목코드'] = df['종목코드'].astype(int).map('{:06d}'.format)
# '종목코드' 기준으로 정렬
df = df.sort_values(by='종목코드')
print(df)
- 실행결과
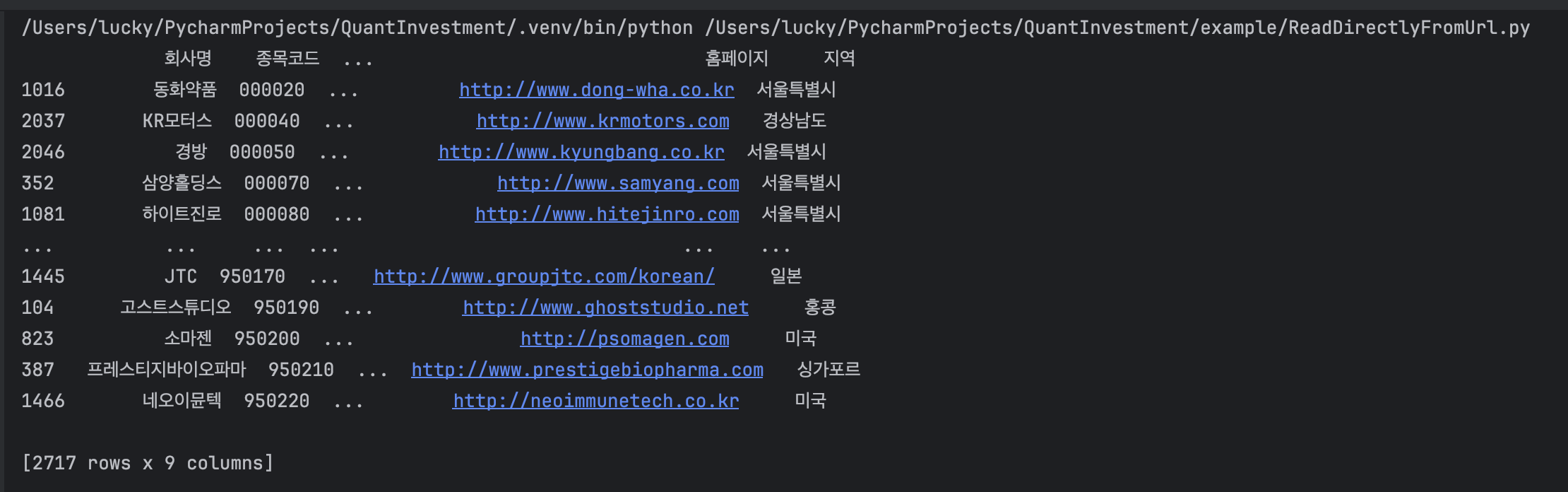
웹에서 일별 주가 데이터 웹 스크래핑 및 캔들 차트 그리기
전체 코드
네이버 증권에서 일별 주가 데이터를 가져오기 위해서는 주식 종목별 일별 시세 페이지의 url을 웹 스크래핑 파이썬 라이브러리인 뷰티풀 수프(Beautiful Soup)를 활용하여 가져옵니다.
Beautiful Soup 라이브러리 설치
1
pip install beautifulsoup4
Beautiful Soup는 html 파서를 지원하지만 속도가 빠르고 유연한 파서 라이브러리인 lxml을 사용합니다.
1
pip install lxml
이제 아래의 과정으로 네이버 증권에서 일별 주가 데이터를 가져오는 코드를 작성합니다.
- 일별 시세 페이지 url 설정
- 맨 뒤 페이지 숫자 구하기
- 전체 페이지 읽어오기
- 차트 출력을 위한 데이터프레임(df) 가공하기
- 캔들 차트 그리기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
from bs4 import BeautifulSoup
import requests
import pandas as pd
from io import StringIO
# 1. 일별 시세 페이지 url 설정
code = '005930'
domain = 'https://finance.naver.com'
uri = '/item/sise_day.nhn?code=' + code
first_page = 1
# URL 설정
url = domain + uri + '&page=' + str(first_page)
# print(url)
# 2. 맨 뒤 페이지 숫자 구하기
response = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
bs = BeautifulSoup(response, 'lxml')
# gpRR = page Right Right (>>)
classPgRR = bs.find('td', class_='pgRR')
# classPgRR의 text 출력 확인
# print(classPgRR.prettify())
# 전체 페이지수 확인
all_pages = classPgRR.a['href'].split('=')[-1]
# print(all_pages) # 708
# 3. 전체 페이지 읽어오기
df_list = [] # 빈 리스트를 사용하여 데이터프레임을 저장
for page in range(1, int(all_pages)+1):
url = domain + uri + '&page=' + str(page)
response = requests.get(url, headers={'User-agent': 'Mozilla/5.0'}).text
# pandas.read_html()에 HTML 문자열을 직접 전달하는 것이 곧 더 이상 지원되지 않음
# StringIO로 감싸서 read_html에 전달
df_list.append(pd.read_html(StringIO(response), header=0)[0])
# pandas 2.0 버전부터 append() 메서드는 더 이상 사용되지 않으며, 대신 pd.concat()을 사용해야 합니다.
df = pd.concat(df_list, ignore_index=True) # 리스트 내 모든 DataFrame을 병합
df = df.dropna() # 결측값 제거
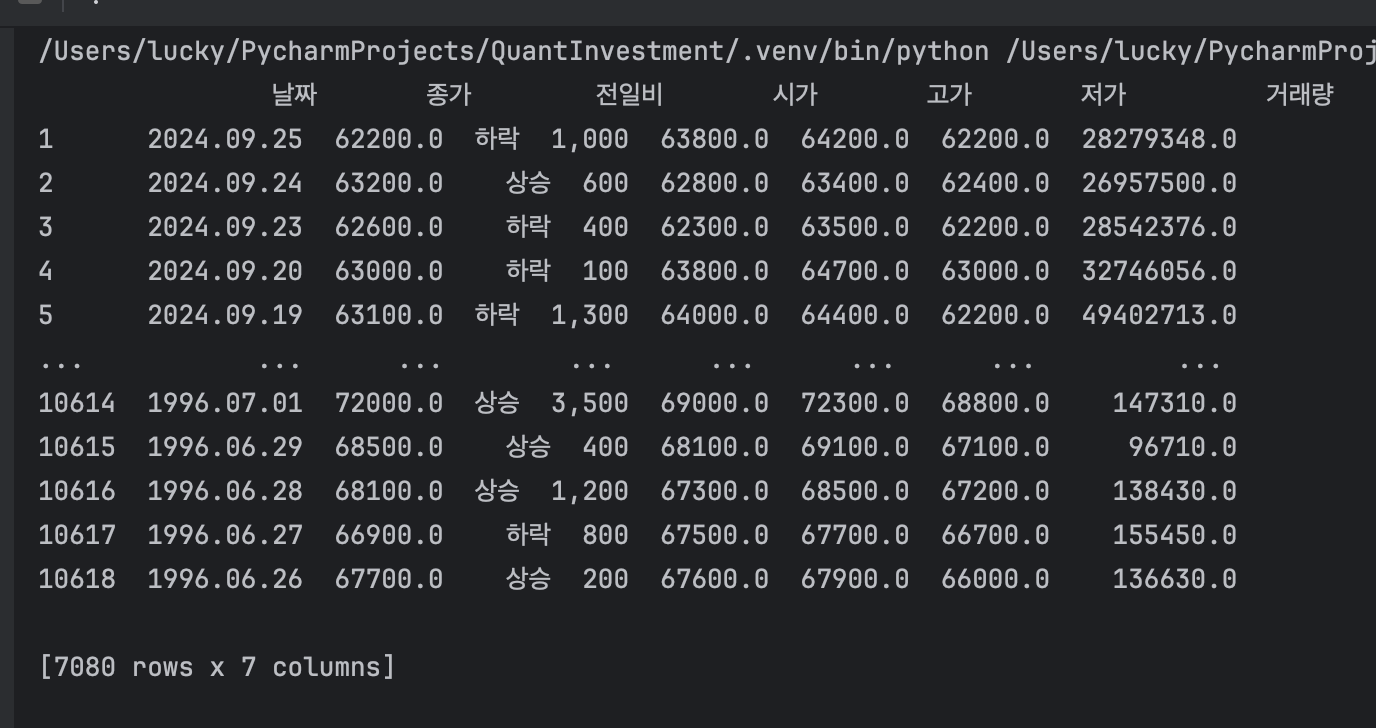
print(df)
여기까지 코드를 실행해보면 아래와 같이 셀트리온(068270)의 일별 주가 데이터를 가져와 출력할 수 있습니다.
도서의 코드 내용이 현재 2024년 9월 기준에서 기술의 변화가 있었기 때문에 코드를 좀 더 보완하여 작성했습니다.
- 실행결과
아래의 코드를 더 추가하여 종가 차트를 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
# 4. 차트 출력을 위한 데이터프레임(df) 가공하기
df = df.iloc[0:30] # 최근 30일 데이터만 사용
df = df.sort_values(by='날짜') # 날짜 기준으로 오름차순 정렬
# 5. 차트 - 종가 그래프
plt.title('Celltrion (close)') # 제목 설정
plt.xticks(rotation=45) # x축 눈금 라벨 회전
plt.plot(df['날짜'], df['종가'], 'co-') # X: 날짜, Y: 종가, 청색(초록색) 실선 그래프
plt.grid(color='gray', linestyle='--') # 그리드 설정
plt.show() # 차트 출력
- 실행결과

이제 mplfinance 라이브러리를 사용하여 캔들 차트를 그려봅니다. mplfinance 라이브러리는 matplotlib 라이브러리를 기반으로 하며, 캔들 차트를 그리기 위한 라이브러리입니다. 위의 종가 차트 코드를 아래와 같이 수정하여 캔들 차트를 그릴 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
import mplfinance as mpf
# 4. 차트 출력을 위한 데이터프레임(df) 가공하기
df = df.iloc[0:30] # 최근 30일 데이터만 사용
df = df.sort_values(by='날짜') # 날짜 기준으로 오름차순 정렬
df = df.rename(columns={'날짜': 'Date', '시가': 'Open', '고가': 'High', '저가': 'Low', '종가': 'Close', '거래량': 'Volume'})
df = df.sort_values(by='Date') # 날짜 기준으로 오름차순 정렬
df.index = pd.to_datetime(df['Date']) # 날짜를 Datetime 형으로 변환
df = df[['Open', 'High', 'Low', 'Close', 'Volume']] # 필요한 열만 선택
# 5. 차트 - 종가 그래프
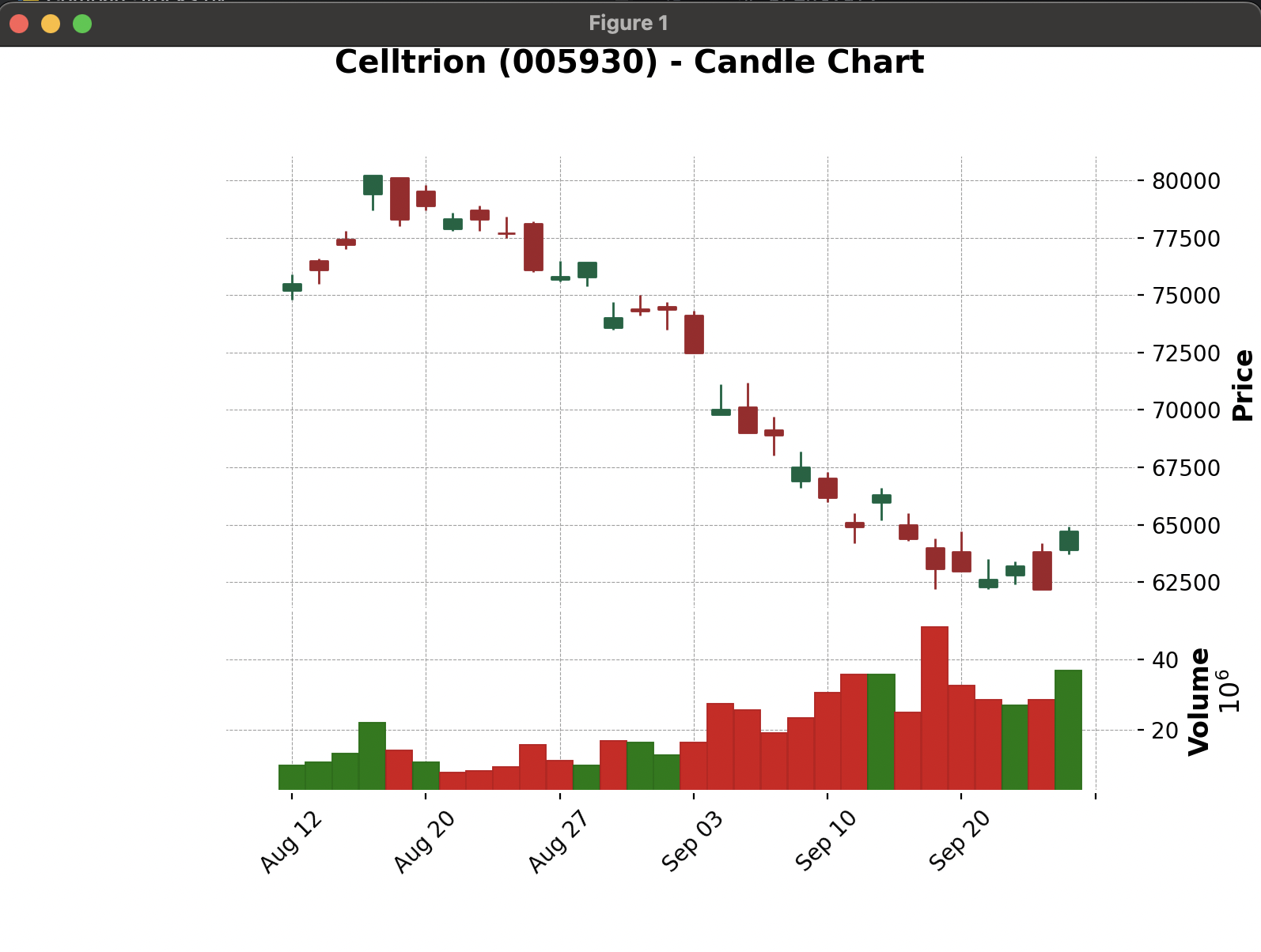
mpf.plot(df, type='candle', volume=True, style='charles', title='Celltrion (005930) - Candle Chart', ylabel='Price', ylabel_lower='Volume')
- 실행결과
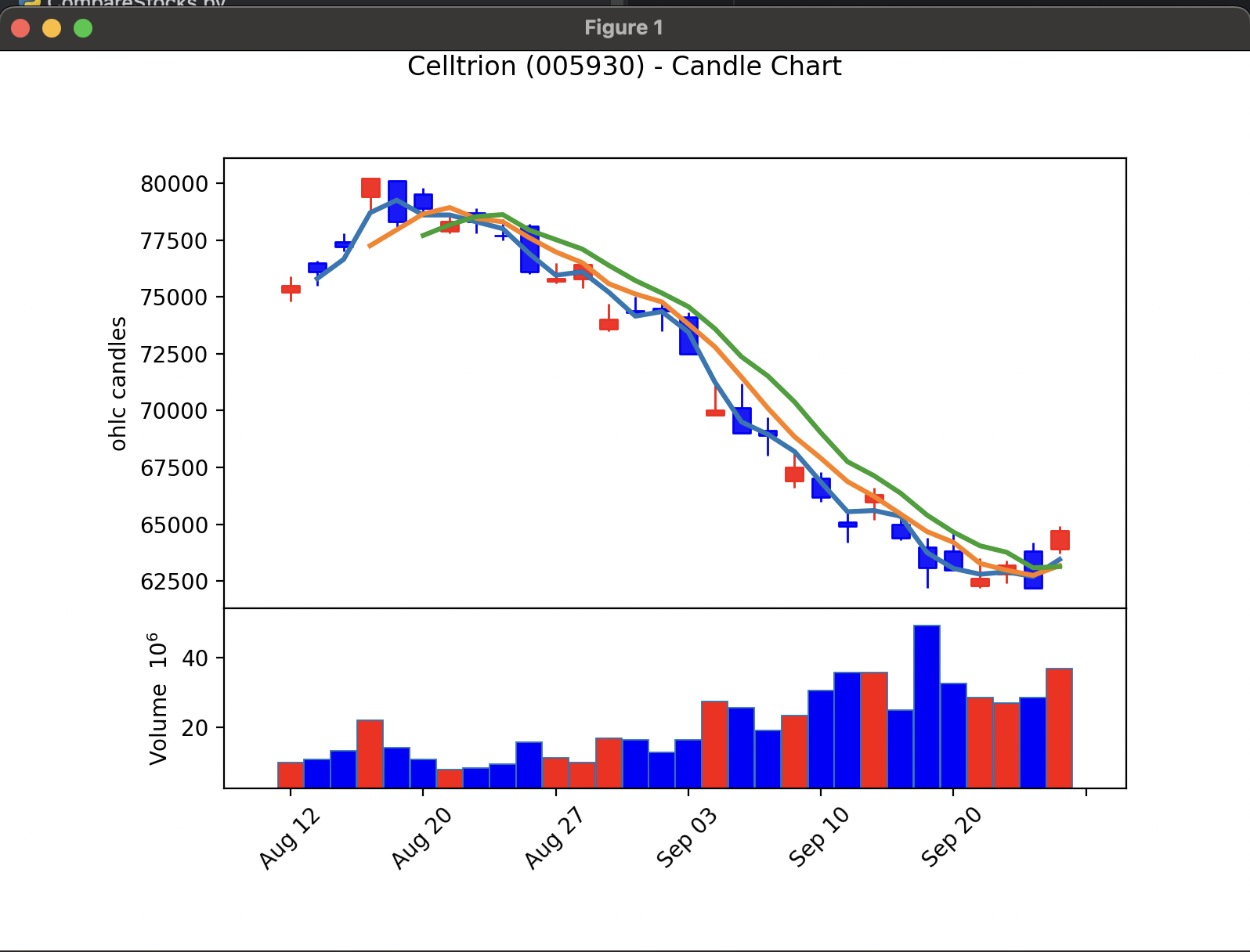
아래와 같이 옵션을 변경하면 다양한 캔들 차트를 그릴 수 있습니다.
1
2
3
4
5
# 5. 차트 - 종가 그래프
kwargs = dict(title='Celltrion (005930) - Candle Chart', type='candle', mav=(2, 4, 6), volume=True, ylabel='ohlc candles')
mc = mpf.make_marketcolors(up='r', down='b', inherit=True)
s = mpf.make_mpf_style(marketcolors=mc)
mpf.plot(df, **kwargs, style=s)
- 실행결과
AI 투자 분석
마치며
이번 포스팅에서는 한국거래소에서 제공하는 상장법인 목록을 다운로드해서 국내 상장 기업 주식 종목코드를 구한 뒤, 네이버 금융(증권)에서 일자별 주가 데이터를 웹 스크래핑하고, 최종 수집한 주가 데이터를 캔들 차트로 그려봄으로써 인터넷에서 증권 데이터를 수집하여 분석하는 과정에 대해 알아보았습니다.
출력된 캔들 차트를 통해 셀트리온(068270)의 최근 30일간의 주가 변동을 확인하고, 양봉과 음봉에 대해 이해할 수 있었습니다.
구현에 있어서 도서의 코드와 Github Copilot에서 제안하는 코드들을 참고하여 입력하고, 실행을 했을 때는 라이브러리나 파이썬 언어의 버전 차이인지 오류가 발생하는 문제가 발견되었습니다.
발생하는 오류는 ChatGPT의 도움을 받아 문제를 해결하고, 실행환경에 필요한 라이브러리를 추가로 설치하며 문제를 해결했습니다.
코드를 실행할 때마다 URL에서 데이터를 가져오는 것은 서버에 부담을 줄 수 있으며, 가져오는 데이터의 양이 많기 때문에 시간이 오래 걸릴 수 있습니다.
24년 9월 기준 2,716개의 상장 기업의 데이터를 가져오는 것은 꽤 시간이 오래 걸릴 것으로 예상되고, 서버에 부하를 줄이는 방향에 대해 고민해봐야겠습니다.
데이터를 가져오면 데이터베이스에 적재하여 사용하는 방법으로 변경해야겠습니다.
포스팅의 피드백은 cremazer@gmail.com으로 보내주시면 포스팅을 작성하는데 반영하도록 하겠습니다.
참고 도서
참고 사이트
“이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.”